Figure 1: Codes postaux manuscrits
Abstract
Dans le contexte où l’apprentissage automatique est en passe de devenir une méthode de plus en plus appliquée dans des différents domaines informatiques pendant ces dernières vingtaine d’années, le réseau de neurones, en tant que l’un des modèles de calcul plus important du domaine, très utilisés notemment dans la reconnaissance d’objets, est devenu un enjeu dans le monde de la recherche informatique.
On va développer ici, dans cet article, un réseau de neurone particulier visant à reconnnaître des codes postaux manuscrits issus des lettres proposées par le service postal des Etats-Unis. Mots-clés. Apprentissage, rétro-propagation, reconnaissance d’objets, réseau de neurones.
Le réseau de neurones est une approche inspirée fondamentalement du système biologique, à proprement parler du fonctionnement des neurones biologiques, qui fournit un mécanisme perceptif indépendant des idées du programmeur.
Dans ses travaux précédents, Yann LeCun avait prouvé que des réseaux de neurones peuvent nous aider à gérer des problèmes de la perception invariante (chiffres, lettres, etc). Il a aussi montré que l’introduction des notions de la localisation des caractéristiques et le poids partagé peut considérablement améliorer la performance du réseau en réduisant son entropie. On appelle tels réseaux les réseaux convolutionnaires.
Dans cet article, on va essayer d’adapter ce type de réseau à un problème réel, la reconnaissance des chiffres manuscrits issus des lettres de U.S. Mail, en s’aidant de l’algorithme de rétro-propagation[3], dont on va détailler le principe plus tard dans l’article. Contrairement à ce qui a été fait avant par Denker, cette fois-ci, on va présenter directement les images à notre réseau au lieu de lui passer des vecteurs caractéristiques. Ceci montre la puissance de la rétro-propagation sur le traitement des informations de bas niveau.
La base de données servant à l’entraînement et les tests du réseau a été proposée par le service postal des Etats-Unis. Il y a, entre autres, 7291 exemplaires de chiffres issus des codes postaux manuscrits qui sont réservés pour l’entraînement et 2007 exemplaires qui servent à tester la performance. Les chiffres sont écrits par différentes personnes, avec différentes tailles, différents styles d’écriture et différents outils d’écriture.
Avant toutes choses, on doit déjà repérer les chiffres sur les enveloppes, puis les séparer les uns les autres. Ceci a été fait, par contre, par le service postal même.
Ensuite, une procédure de normalisation a été introduite afin de réduire les images digitales d’une taille standard d’environ 40x60 pixels à une taille de 16x16 pixels.
Avant d’aller élaborer notre struture du réseau, on va d’abord introduire deux notions essentielles dans notre approche, la localisation des caractéristiques et le poids partagé. Ces deux notions nous permettent de réduire largement le nombre de paramètres indépendants dans le réseau et ainsi augmenter considérablement la performance de la rétro-propagation.
L’extraction de caractéristique consiste en des transfromations mathémtiques calculées sur les pixels d’une image numérique. C’est une étape préable à la classification. Dans notre cas, au lieu de calculer les caractéristiques globales, on calcule seulement les caractéristiques locales autour des points d’intétêt.
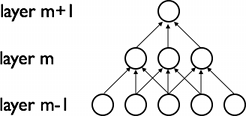
Ainsi, le poids d’un synapse de la couche m est calculé à partir seulement d’un sous-ensemble de la couche précedente. On peut illustré cette idée avec un exemple suivant[1]:
On voit dans le graphe que les synapses dans la couche m sont reliés seulement à 3 neurones de la couche m - 1.
Comme la position exacte d’une caractéristique n’a aucun impact sur la classification, on peut se permettre de perdre certaines informations sur la position dans notre processus. Néanmoins, la position approximative d’une caractéristiques doit être conservée afin que les couches d’ordre supérieur puissenet détecter les caractéristiques plus complexes.
Comme les différents caractéristiques d’un objet peuvent apparaître dans différents lieux sur une image, il est donc judicieux d’avoir des détecteurs de caractéristiques. Ceci se fait facilement avec des poids partagés.
Le poids partagé consiste à imposer une contrainte d’egalité du poids sur les synapses afin de former des "feature maps". Un exemple:
Dans le graphe ci-dessus, il y a 3 synapses appartenant à une "feature map", les poids de la même couleur ont été partagés. La descente du gradient reste valable pour les poids partagés, il suffit de considérer le gradient du poids partagé comme la somme des gradients des paramètres qui sont partagés.
Cette approche du poids partagé, qui est décrite plus précisément dans [3], nous permet de détecter une caractéristique particulère sans se soucier de trouver sa position exacte. Ainsi, elle augmenter énormément l’efficacité de l’apprentissage.
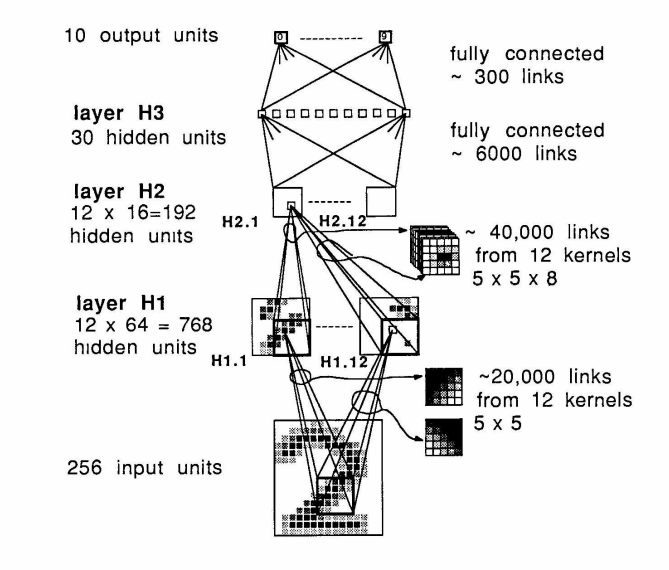
Il y a 5 couches dans notre réseau, y compris une couche d’entrée, 3 couches cachées H1, H2, H3 et une couche de sortie dont chaque couche prend ses entrées sur les sorties de la couche précédente. A chaque synapse est associé un poids synaptique. La mise en place des différentes couches reviendrait en effet à mettre en cascade plusieurs matrices de transformation et pourrait se ramener à une seule matrice, produit des autres.
La couche H1 et la couche H2 sont divisées respectivement en 12 8x8 "feature maps" et 12 4x4 "feature maps". La couche H3 comprend 30 synapses alors que la couche de sortie comprend 10 synapses. Les connexions reliant les couches H1, H2 et les couches H2, H3 sont établies suivant l’approche du poids partagé sous certaines contraintes qui sont illustrées par le graphe ci-dessous.
On donne quelques chiffres pour résumer, il y a au total 1256 synapses, 64660 liaisons et 9760 paramètres indépendants. Le nombre de paramètres indépendants reste donc assez limité par rapport au nombre de liaisons.
Notre réseau étant un réseau à rétro-propagation, on va donc décrire ici le principe de ce fameux algorithme[3]:
On va répéter cette procédure jusqu’à ce que l’algorithme converge.
Les simulations se font sur une machine SUN-4/260 en utilisant un simulateur SN à rétro-propagation.
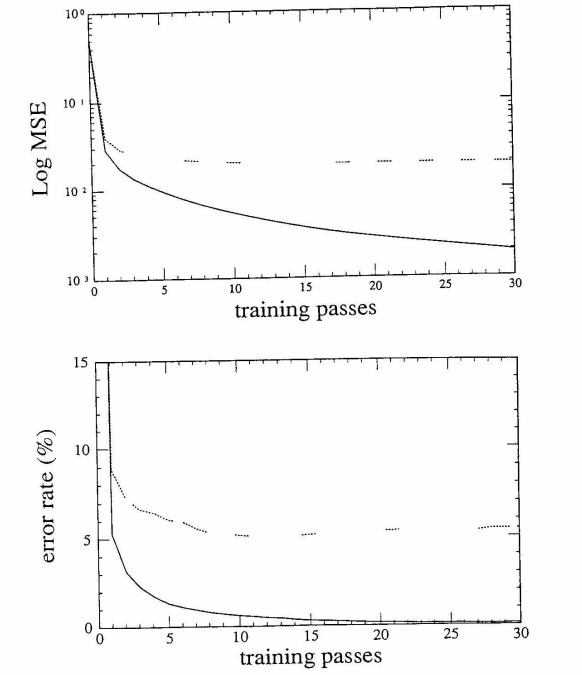
A chaque passage de l’ensemble d’apprentissage, on mesure à la fois la performance sur l’ensemble d’apprentissage et l’ensemble de test. Et on passe au total 23 fois l’ensemble d’apprentissage.
Après ces 23 passages, le MSE (Mean square error) des sorties finales est 2.5 × 10-3 sur l’ensemble d’apprentissage et 1.8 × 10-2 sur l’ensemble de test. Le pourcentage des patterns mal classés est 0.14% sur l’ensemble d’apprentissage et 5.0% sur l’ensemble de test.
La convergence arrive extrêmement vite, cela signifie que la rétro-propagation peut très bien s’adapter à de telles tâches réelles. Ceci est dû au fait que les données réelles ont une très riche redondance.
Voici un lien pour une démo du LeNet-5 sur le site personnel de Yann LeCun. LeNet-5 est la dernière version du réseau convolutionnaire qu’ils ont développé pour la reconnaissance des chiffres manuscrits: http://yann.lecun.com/exdb/lenet/
Etant donné que la base de données d’apprentissage a une taille assez considérable, le temps de la convergence de notre réseau semble assez résonable. Le résultat final est donc assez satisfaisant, et ceci montre aussi que la rétro-propagation peut effectivement jouer un rôle essentiel lors du traitement d’un problème réel.
Pourtant, il faut bien noter que notre réussite est dû au fait que nos données ont une riche redondance et que nous avons imposé certaines contraintes sur notre réseau. Or, dans un cas plus général, la rétro-propagation mène à une convergence assez lente.
[1] Convolutional neural networks. http://deeplearning.net/tutorial/lenet.html.
[2] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. Backpropagation applied to handwritten zip code recognition. Neural Computation, 1(4):541–551, Winter 1989.
[3] D. E. Rumelhart, G. E. Hinton, and R. J. Williams. Learning internal representations by error propagation. pages 318–362, 1986.