Adaptive Methods for Optimisation in Stochastic Environments




Introduction
Sequential optimisation in a stochastic environment
We aim to maximise a target function
based on a sequence of function values...
Use cases
A/B/C Testing
(Source: Julie Paci)
Design of clinical trials
(Source: cbinsights.com)
Hyper-parameter optimization (HPO)
(Source: Ramraj Chandradevan)
Multi-armed bandits
A bandit model is denoted by \(\mu\)
Learning protocol: at each round \(t\), choose an arm \(I_t\) to play and observes a stochastic/noisy reward \(r_{I_t}\sim\nu_{I_t}\) that follows the corresponding underlying distribution.
Learning goals
- Reward maximisation: trade-off between exploration and exploitation
- Best-arm identification (BAI):
-
$$\mu^\star = \textcolor{red}{\max}_i \mu_i$$
$$I^\star = \textcolor{red}{\operatorname{arg\,max}}_i \mu_i$$
-
Outline
- Part 1: Finite Search Space
- Bayesian best-arm identification
- Extensions to the linear case
- Part 2: Infinite or Continuous Search Space
- Apply Bayesian algorithms to HPO
Part 1: Finite Search Space
Bayesian Best-Arm Identification
Formally, a BAI algorithm is composed of:
- a sampling rule \(\hat{I}\)
- a stopping rule \(\tau\)
- fixed-budget: stops when reach the budget \(\tau = n\) (Audibert and Bubeck, 2010; Gabillon et al., 2013; Karnin et al., 2013)
- fixed-confidence: stops when the probability of outputting a wrong arm is less than \(\delta\), minimize \(\mathbb{E}[\tau_\delta]\) (Even-Dar et al., 2003; Kalyanakrishnan et al., 2013; Jamieson et al., 2014; Garivier and Kaufmann 2016, Qin et al., 2017)
- a decision rule
- outputs a guess \(J_\tau\) of the best arm \(I^\star\) when the algorithm stops
We are interested in Top-Two Thompson Sampling (Russo, 2016)

Why?
- Anytime BAI algorithm: does not depend on \(n\) or \(\delta\) (Jun and Nowak, 2016)
- A Bayesian competitor for BAI as Thompson sampling to UCB for regret minimizing?
- Strong practical performance?
- Does not need to calibrate 'conservative' confidence regions
What is known about TTTS... (posterior convergence)
Theorem (Russo, 2016) Under TTTS and under the some boundedness assumptions on the prior and the parameter space, it holds a.s. \[ \lim_{n\rightarrow{\infty}} -\frac{1}{n}\log(1-\alpha_{n,I^\star}) = \textcolor{lightskyblue}{\frac{1}{T_{\beta}^\star(\boldsymbol{\mu})}}, \] where \[ \quad \alpha_{n,i} \triangleq \Pi_{n}(\theta_i \gt \max_{j\neq i}\theta_j). \]
What is known about TTTS... (characteristic time)
Definition Let \(\Sigma_K = \{\omega : \sum_{k=1}^K \omega_k = 1, \omega_k \geq 0\}\) and define for all \(i\neq I^\star\) \[ C_i(\omega,\omega') \triangleq \min_{x\in\mathcal{I}} \omega d(\mu_{I^\star};x) + \omega' d(\mu_i;x), \] where \(d(\mu,\mu')\) is the KL-divergence. We define \[ \textcolor{lightskyblue}{T_{\beta}^\star(\boldsymbol{\mu})^{-1}} \triangleq \max_{\substack{\omega \in \Sigma_K\\\omega_{I^\star}=\beta}}\min_{i\neq I^\star} C_i(\omega_{I^\star},\omega_i). \]
In particular, for Gaussian bandits... \[ \textcolor{lightskyblue}{T_{\beta}^\star(\boldsymbol{\mu})^{-1}} = \max_{\omega:\omega_{I^\star}=\beta}\min_{i\neq I^\star} \frac{(\mu_{I^\star}-\mu_i)^2}{2\sigma^2(1/\omega_i+1/\beta)}. \]
Limitations of TTTS
- Existing guarantees do not apply to standard choices of conjugate priors. (AISTATS 20)
- What can we say about the sample complexity in the fixed-confidence setting?
- Can we have finite-time guarantees?
Bayesian Best-Arm Identification
- Theoretical insights
Main results
Sample complexity
Theorem 3 (AISTATS 20) The TTTS sampling rule coupled with the Chernoff stopping rule form a \(\delta\)-correct BAI strategy. If all arm means are distinct, \[ \limsup_{\delta\rightarrow{0}} \frac{\mathbb{E}[\tau_{\delta}]}{\log(1/\delta)} \leq \textcolor{lightskyblue}{T_{\beta}^\star(\boldsymbol{\mu})}. \]
Lower bound (Garivier and Kaufmann, 2016): \[\liminf_{\delta \rightarrow 0}\frac{\mathbb{E}[\tau_\delta]}{\log(1/\delta)} \geq \textcolor{lightskyblue}{T_{\beta}^\star(\boldsymbol{\mu})}.\]
Proof sketch
\(\delta\)-correctness
Stopping rule: \[ \tau_\delta^{\text{Ch.}} \triangleq \inf \left\lbrace n \in \mathbb{N} : \max_{i \in \mathcal{A}} \min_{j \in \mathcal{A} \setminus \{i\} } \textcolor{lightskyblue}{W_{n}(i,j)} \gt d_{n,\delta} \right\rbrace. \]
Transportation cost: \(\mu_{n,i,j} \triangleq (T_{n,i}\mu_{n,i} +T_{n,j}\mu_{n,j})/(T_{n,i}+T_{n,j})\), then we define \[ \color{lightskyblue}{W_n(i,j)} ≜ \left\{ \begin{array}{ll} 0 & \operatorname{if} \mu_{n,j} \geq \mu_{n,i},\\ W_{n,i,j}+W_{n,j,i} & \operatorname{otherwise}, \end{array}\right. \] where \(W_{n,i,j} \triangleq T_{n,i} d\left(\mu_{n,i},\mu_{n,i,j}\right)\) for any \(i,j\).
In particular, for Gaussian bandits: \[ \color{lightskyblue}{W_n(i,j)} = \dfrac{(\mu_{n,i}-\mu_{n,j})^2}{2\sigma^2(1/T_{n,i}+1/T_{n,j})}\mathbb{1}\{\mu_{n,j}<\mu_{n,i}\}. \]
Theorem (AISTATS 20) The TTTS sampling rule coupled with the Chernoff stopping rule with a threshold \(d_{n,\delta} \simeq \log(1/\delta) + c\log(\log(n))\) and the recommendation rule \(J_t = \operatorname{arg\,max}_i \mu_{n,i}\), form a \(\delta\)-correct BAI strategy.
Bayesian stopping rule: \[\tau_{\delta} ≜ \inf \left\{ n\in\mathbb{N}:\max_{i\in\mathcal{A}} \textcolor{limegreen}{\alpha_{n,i}} \geq c_{n,\delta} \right\}\,.\]
Proof sketch
Sufficient condition for \(\beta\)-optimality
Lemma (AISTATS 20) Let \(\delta,\beta\in (0,1)\). For any sampling rule which satisfies \(\mathbb{E}[\textcolor{lightskyblue}{T_{\beta}^\epsilon}] \lt \infty\) for all \(\epsilon \gt 0\), we have \[ \limsup_{\delta\rightarrow{0}} \frac{\mathbb{E}[\tau_{\delta}]}{\log(1/\delta)} \leq T_{\beta}^\star(\boldsymbol{\mu}), \] if the sampling rule is coupled with the Chernoff stopping rule.
\(\textcolor{lightskyblue}{T_{\beta}^\epsilon} \triangleq \inf \left\{ N\in\mathbb{N}: \max_{i\in\mathcal{A}} \vert T_{n,i}/n-\omega_i^\beta \vert \leq \epsilon, \forall n \geq N \right\}\).
Proof sketch
Core theorem
Theorem (AISTATS 20) Under TTTS, \(\mathbb{E}[\textcolor{lightskyblue}{T_{\beta}^\epsilon}] \lt +\infty\).
Bayesian Best-Arm Identification
- Computational improvement
TTTS
T3C (Top-Two Transportation Cost)

Main results
Sample complexity
Theorem (AISTATS 20) The T3C sampling rule coupled with the Chernoff stopping rule form a \(\delta\)-correct BAI strategy. If all arm means are distinct, \[ \limsup_{\delta\rightarrow{0}} \frac{\mathbb{E}[\tau_{\delta}]}{\log(1/\delta)} \leq \textcolor{lightskyblue}{T_{\beta}^\star(\boldsymbol{\mu})}. \]
Illustrations
Time consumption
| Sampling rule | T3C | TTTS | Uniform |
|---|---|---|---|
| Exec. time (s) | \(1.6 \times 10^{-5}\) | \(2.3 \times 10^{-4}\) | \(6.0 \times 10^{-6}\) |
Choice of \(\beta\)
- In our experiments: \(\beta=1/2\)
- Adaptive \(\beta\)?
Illustrations
Average stopping time (Bernoulli)
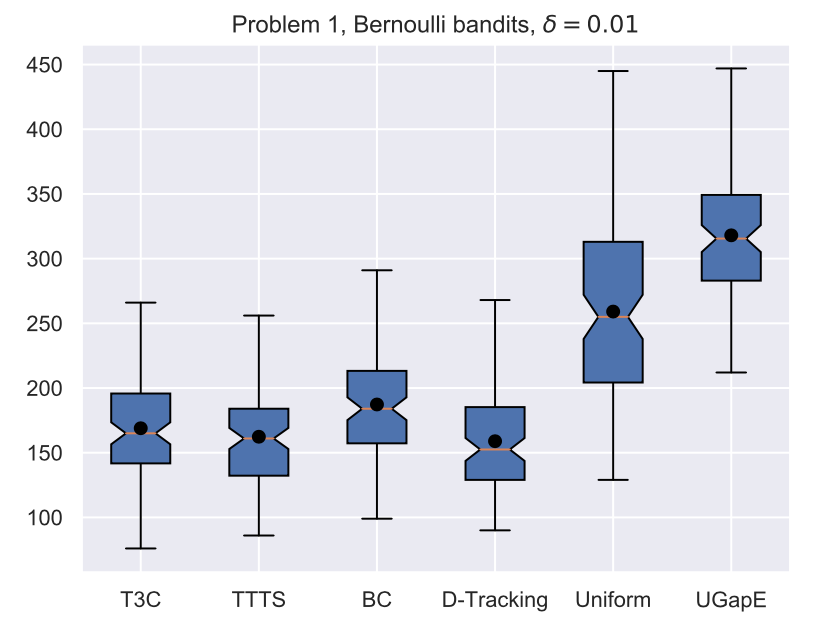
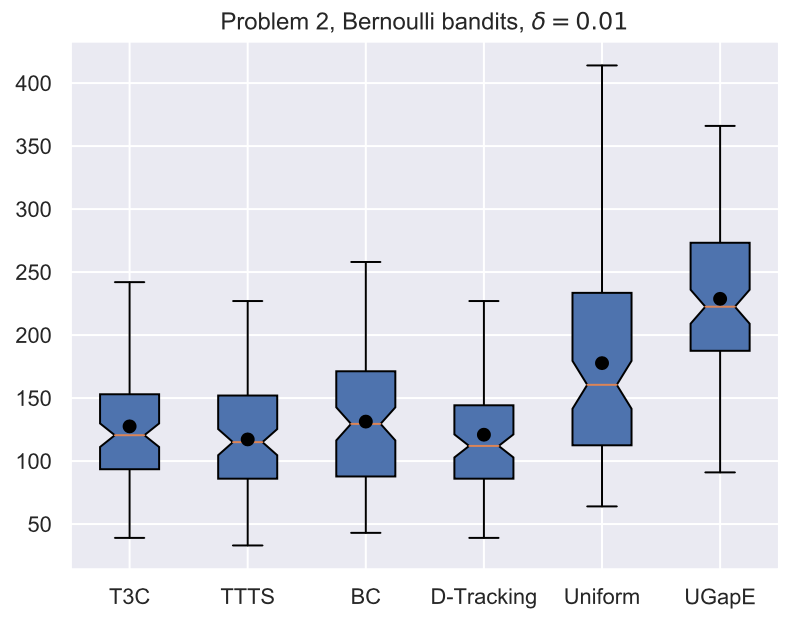
Illustrations
Average stopping time (Gaussian)
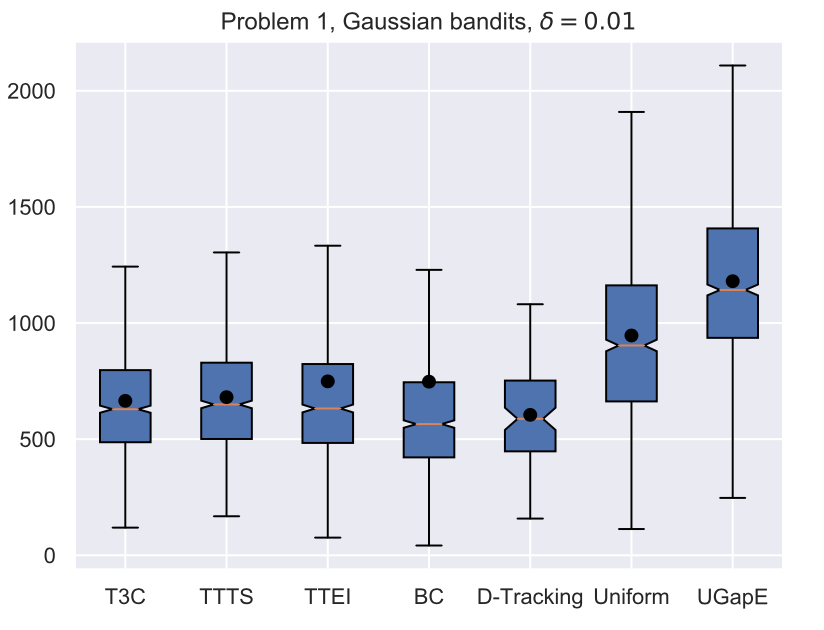
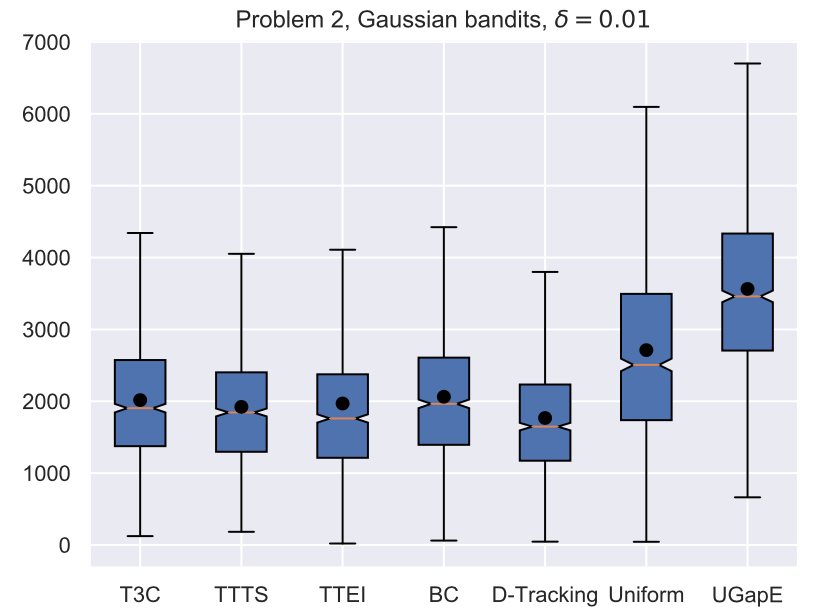
Extensions to the Linear Case
BAI for linear bandits
- Each arm (context) is a vector \(\boldsymbol{x}\in\mathbb{R}^d\).
- Unknown regression parameter \(\boldsymbol{\theta}\in\mathbb{R}^d\).
- \(\mu_i = \boldsymbol{x_i}^\top\boldsymbol{\theta}\), in this part: a bandit model is simply characterised by \(\boldsymbol{\theta}\).
- \(r_n = \boldsymbol{x}_{I_n}^\top\boldsymbol{\theta}+\epsilon_n\)
- Goal: \(\boldsymbol{x^\star} = I^\star(\boldsymbol{\theta}) \triangleq \operatorname{arg\,max}_{\boldsymbol{x}\in\mathcal{X}}\boldsymbol{x}^\top\boldsymbol{\theta}\).
- Fixed-confidence setting: show that \(\mathbb{P}[{\boldsymbol{x}_{J_{\tau_\delta}}\neq \boldsymbol{x}^\star}] \leq \delta,\) while minimising the expected number of samples \(\mathbb{E}[\tau_\delta]\) (Soare et al., 2014)
BAI for linear bandits
- Problem: no asymptotically optimal algorithms before (Soare et al., 2014; Xu et al., 2018; Tao et al., 2018; Fiez et al., 2019)
- Can TTTS/T3C be extended to the linear case?
- If not, what else can we do? (ICML 20)
Problem formulation
Common assumptions
- Assumption We assume that \(\epsilon_n \sim \mathcal{N}(0,\sigma^2)\) is conditionally independent from the past.
- Assumption We assume that \(\exists L>0\), \(\forall \boldsymbol{x}\in\mathcal{X}, \left\lVert\boldsymbol{x}\right\rVert\leq L\), where \(\left\lVert\boldsymbol{x}\right\rVert\) denotes the Euclidean norm of the vector \(\boldsymbol{x}\).
- Assumption is finite
Problem formulation
Linear estimator
- Regularised least-square estimation: \[\boldsymbol{\hat{\theta}}_n^{\lambda} = (\lambda \mathbb{I}_d + \boldsymbol{A}_{\boldsymbol{X_n}})^{-1}\boldsymbol{b}_{\boldsymbol{X}_n}\]
- Design matrix:
- Response vector:
- \(\lambda\in\mathbb{R}\) is the regularisation parameter.
- \(\boldsymbol{\Lambda}_{\boldsymbol{\omega}} \triangleq \sum_{i=1}^K \omega_i\boldsymbol{x}_i\boldsymbol{x}_i^\top\), where \(\boldsymbol{\omega} = (\omega_1,\cdots,\omega_K)\in\Sigma_K\).
Lower bound
Definition For any arm \(\boldsymbol{x}\in\mathcal{X}\) we define its alternative set, denoted by Alt(\(\boldsymbol{x}\)) the set of parameters where \(\boldsymbol{x}\) is not the best arm, i.e.
- Lower bound: for any \(\delta\)-correct strategy, we have \[\mathbb{E}[\tau_\delta] \geq T^\star(\boldsymbol{\theta})\log(\frac{1}{3\delta}).\]
- Characteristic time: \[T^\star(\boldsymbol{\theta})^{-1} \triangleq \max_{\boldsymbol{\omega} \in \Sigma_K} \inf_{\boldsymbol{\theta}'\in \text{Alt}(I^\star(\boldsymbol{\theta}))} \frac{1}{2}\left\lVert\boldsymbol{\theta} - \boldsymbol{\theta}'\right\rVert_{\boldsymbol{\Lambda}_{\boldsymbol{\omega}}}^2\]
- In particular: \[T^\star(\boldsymbol{\theta}) \triangleq \inf_{\boldsymbol{\omega}\in\Sigma_K}\max_{\boldsymbol{x}\neq \boldsymbol{x}^\star} \frac{2\left\lVert\boldsymbol{x}^\star - \boldsymbol{x}\right\rVert^2_{\boldsymbol{\Lambda}_{\boldsymbol{\omega}}^{-1}}}{(\boldsymbol{x}^\top\boldsymbol{\theta}-(\boldsymbol{x}^\star)^\top\boldsymbol{\theta})^2}\]
Direct adaptation of TTTS/T3C
- Prior: \(\boldsymbol{\theta}\sim \mathcal{N}(0,\sigma^2/\lambda\mathbb{I}_d) \rightarrow\mathcal{N}(\hat{\boldsymbol{\theta}}^\lambda_n,\hat{\boldsymbol{\Sigma}}_n)\)
- Posterior update: \[(\hat{\boldsymbol{\Sigma}}_n)^{-1} = \frac{\lambda}{\sigma^2}\mathbb{I}_d + \frac{1}{\sigma^2}\sum_{t=1}^n \hat{\boldsymbol{x}}_t\hat{\boldsymbol{x}}_t^\top \quad \text{and} \quad \hat{\boldsymbol{\theta}}^\lambda_n = \frac{1}{\sigma^2}\hat{\boldsymbol{\Sigma}}_n \boldsymbol{b}_{\boldsymbol{X}_n}.\]
- Transportation cost: \[W_n(i,j) = \frac{(\boldsymbol{x}_i^\top\hat{\boldsymbol{\theta}}^\lambda_n-\boldsymbol{x}_j^\top\hat{\boldsymbol{\theta}}^\lambda_n)^2}{2\left\lVert\boldsymbol{x}_i-\boldsymbol{x}_j\right\rVert_{\hat{\boldsymbol{\Sigma}}_n}^2}\mathbb{I}\left\{\boldsymbol{x}_j^\top\hat{\boldsymbol{\theta}}^\lambda_n<\boldsymbol{x}_i^\top\hat{\boldsymbol{\theta}}^\lambda_n\right\}\]
- Stopping rule: \[\tau_\delta \triangleq \inf \left\lbrace n \in \mathbb{N} : \max_{i \in [K]} \min_{j \neq i } W_{n}(i,j) > d_{n,\delta} \right\rbrace\]
- Decision rule: \[J_n = \text{argmax}_{j}\boldsymbol{x}_j^\top\hat{\boldsymbol{\theta}}_n^{\lambda}\]
Direct adaptation of TTTS/T3C
It can fail...
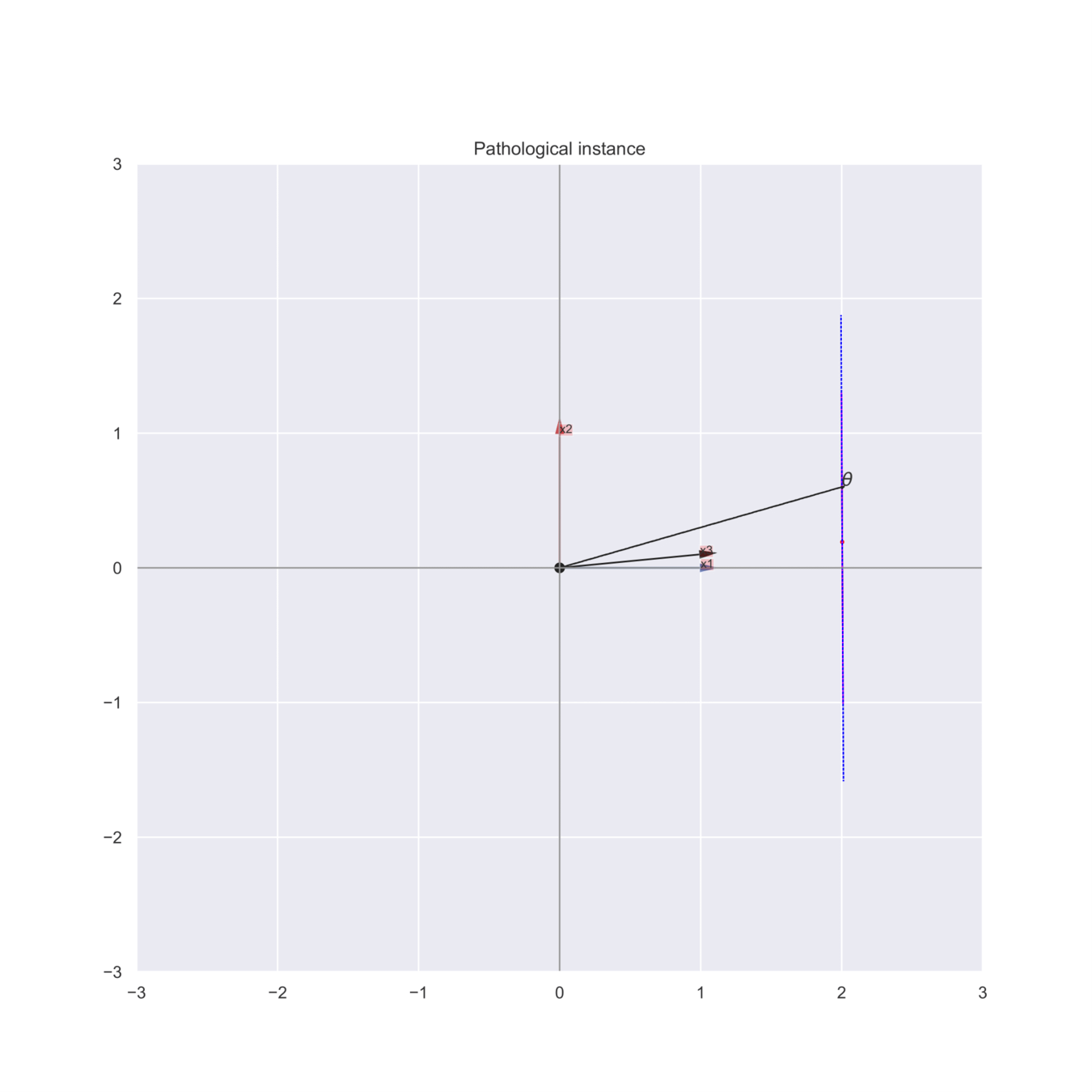
A hard problem instance for linear best-arm identification
A study of BAI complexities
- Estimate uniformly the means of the arms: optimal design \[\mathcal{XX}=\min_{\boldsymbol{\omega}\in\Sigma_K} \max_{\boldsymbol{x}\in\mathcal{X}} \left\lVert\boldsymbol{x}\right\rVert_{\boldsymbol{\Lambda}_{\boldsymbol{\omega}}^{-1}}^2\]
- Estimate uniformly the means of the directions: transductive design \[\mathcal{XY}_{\text{dir}}=\min_{\boldsymbol{\omega}\in\Sigma_K} \max_{\boldsymbol{y}\in\mathcal{Y}_{\text{dir}}} \left\lVert\boldsymbol{y}\right\rVert_{\boldsymbol{\Lambda}_{\boldsymbol{\omega}}^{-1}}^2\] where \[\mathcal{Y}_{\text{dir}}\triangleq\{\boldsymbol{x}-\boldsymbol{x}':\ (\boldsymbol{x},\boldsymbol{x}')\in\mathcal{X}\times\mathcal{X}\}\]
- Estimate the means of the gap-weighted directions: best-arm identification \[T^\star(\boldsymbol{\theta}) = 2 \mathcal{X}\mathcal{Y}^\star(\boldsymbol{\theta}) \triangleq 2 \min_{\boldsymbol{\omega}\in\Sigma_K} \max_{\boldsymbol{y}\in\mathcal{Y}^\star(\boldsymbol{\theta})} \left\lVert\boldsymbol{y}\right\rVert_{\boldsymbol{\Lambda}_{\boldsymbol{\omega}}^{-1}}^2\] where \[\mathcal{Y}^\star \triangleq \left\{ \frac{\boldsymbol{x}^\star(\boldsymbol{\theta})- \boldsymbol{x}}{\left|(\boldsymbol{x}^\star(\boldsymbol{\theta})- \boldsymbol{x})^\top\boldsymbol{\theta}\right|}: \boldsymbol{x}\in\mathcal{X}/\big\{\boldsymbol{x}^\star(\boldsymbol{\theta})\big\} \right\}\]
A study of BAI complexities
Ordering (ICML 20)
BAI as a game
\(T^\star(\boldsymbol{\theta})^{-1}\) can be regarded as the value of a zero-sum game between a learner playing action \(\boldsymbol{x}\) according to a weight vector \(\boldsymbol{\omega}\) and the nature playing an alternative \(\boldsymbol{\theta}'\):
Leads to the algorithm of LinGame which is asymptotically optimal... (ICML 20)
Ensure a ε-approximation of the saddle point of the lower-bound game.
Illustrations
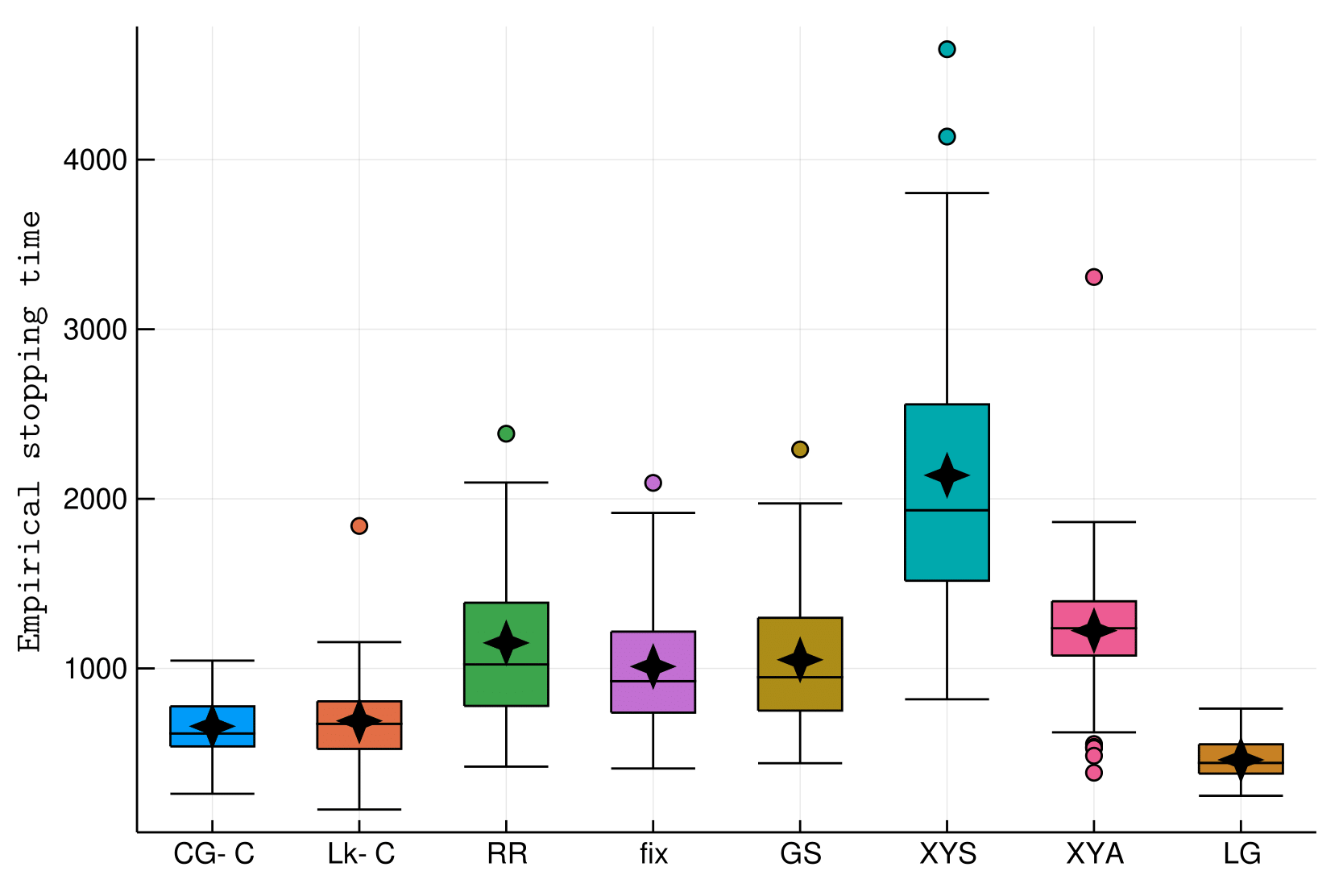
The usual hard instance (with different \(\delta\))
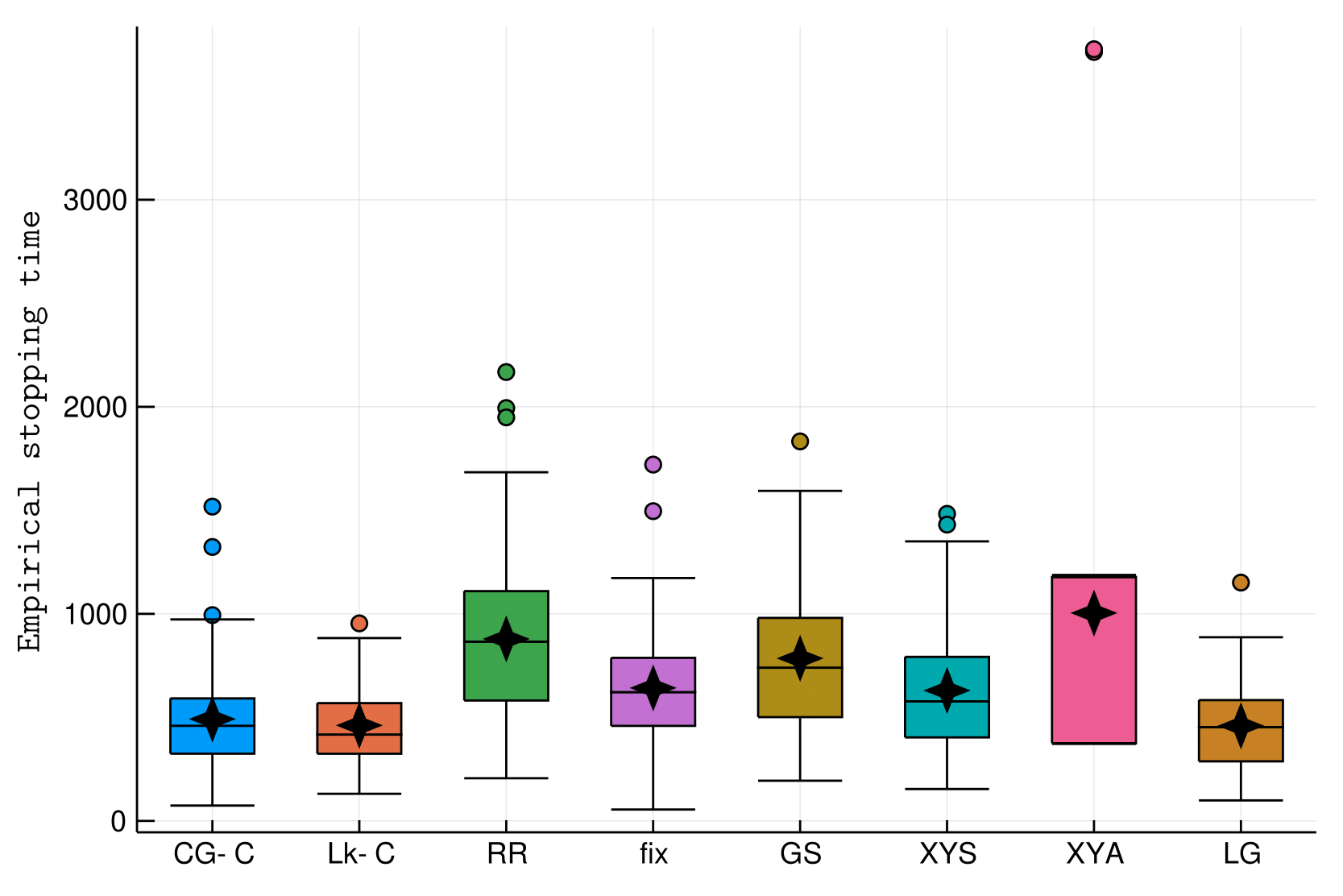
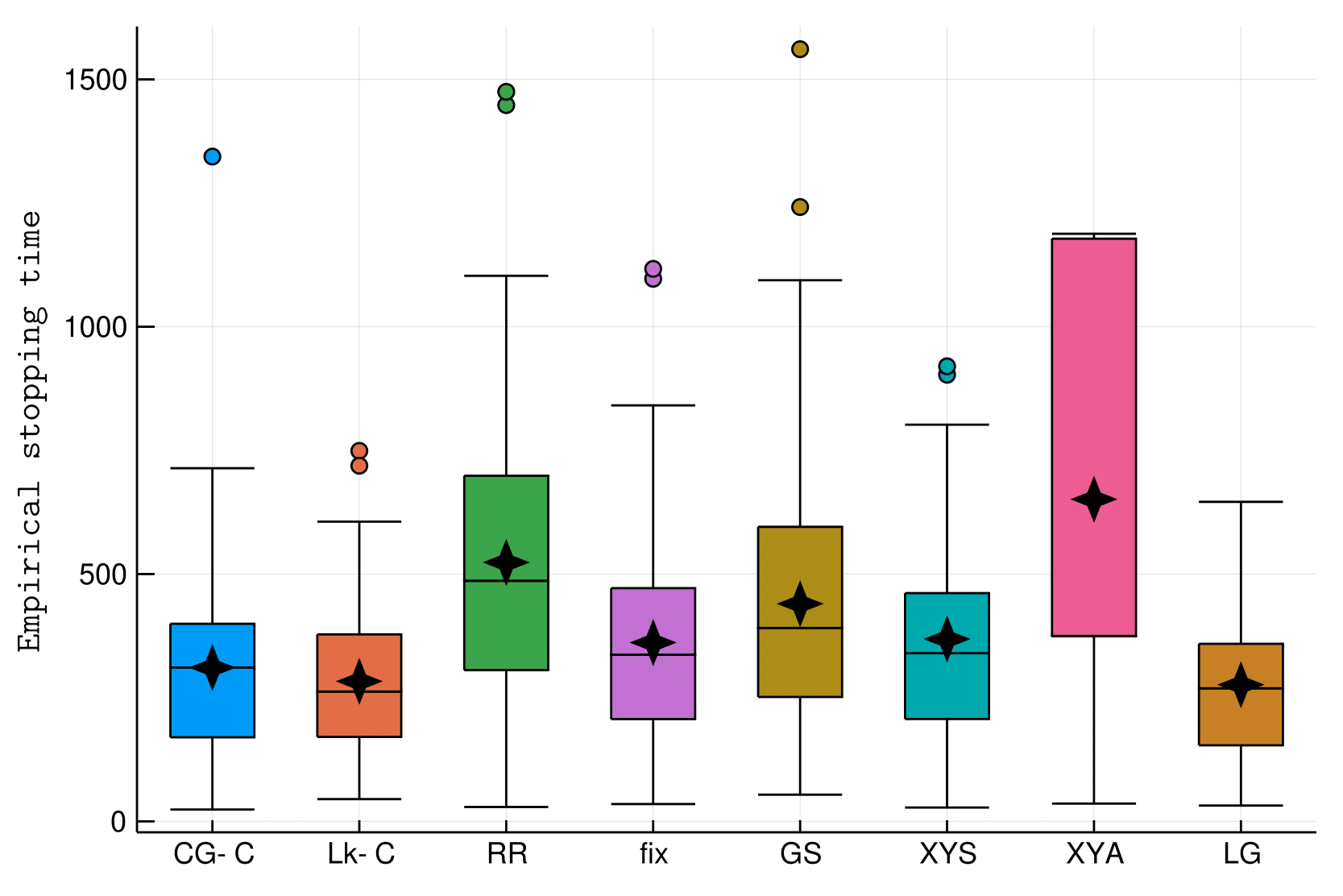
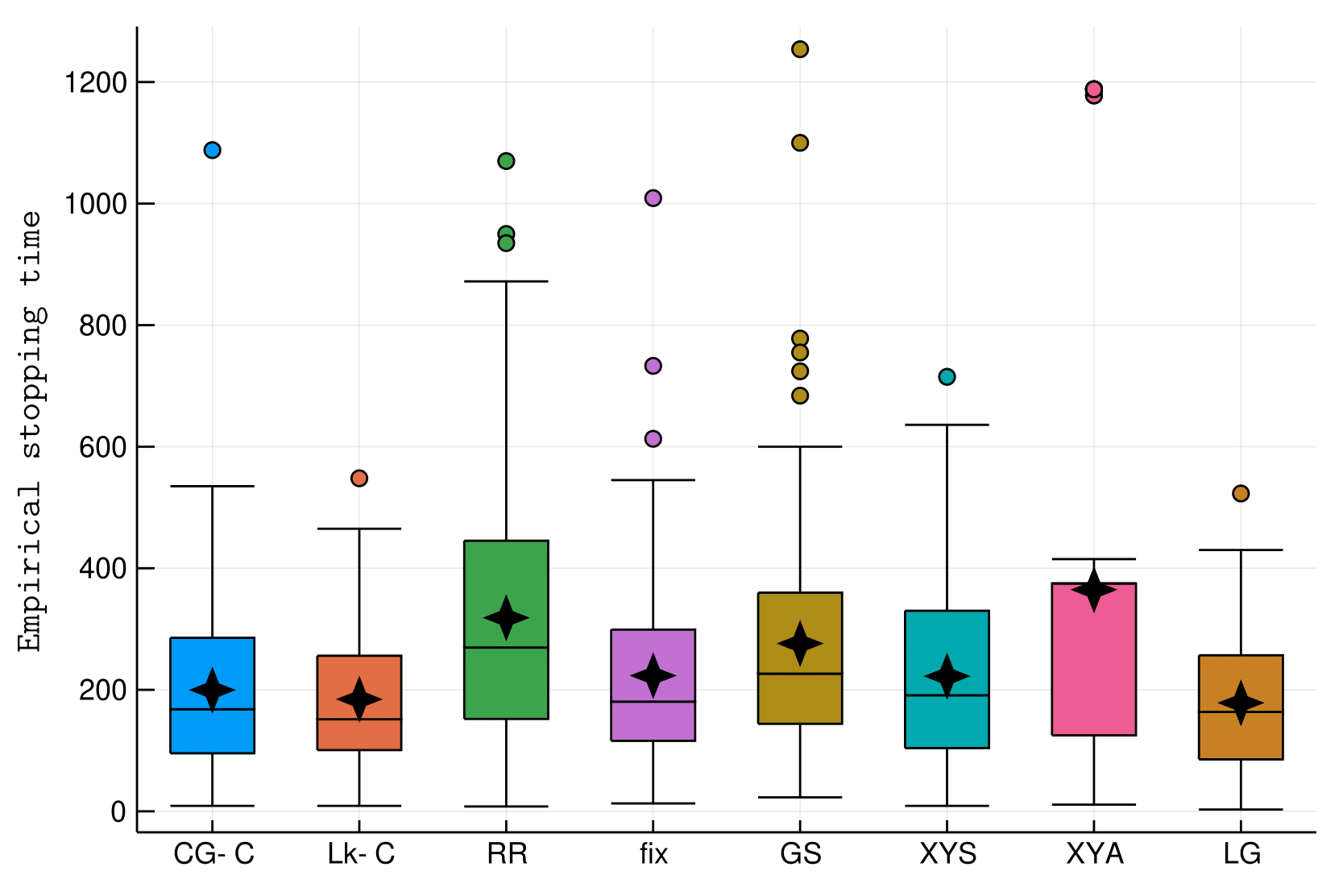
Illustrations
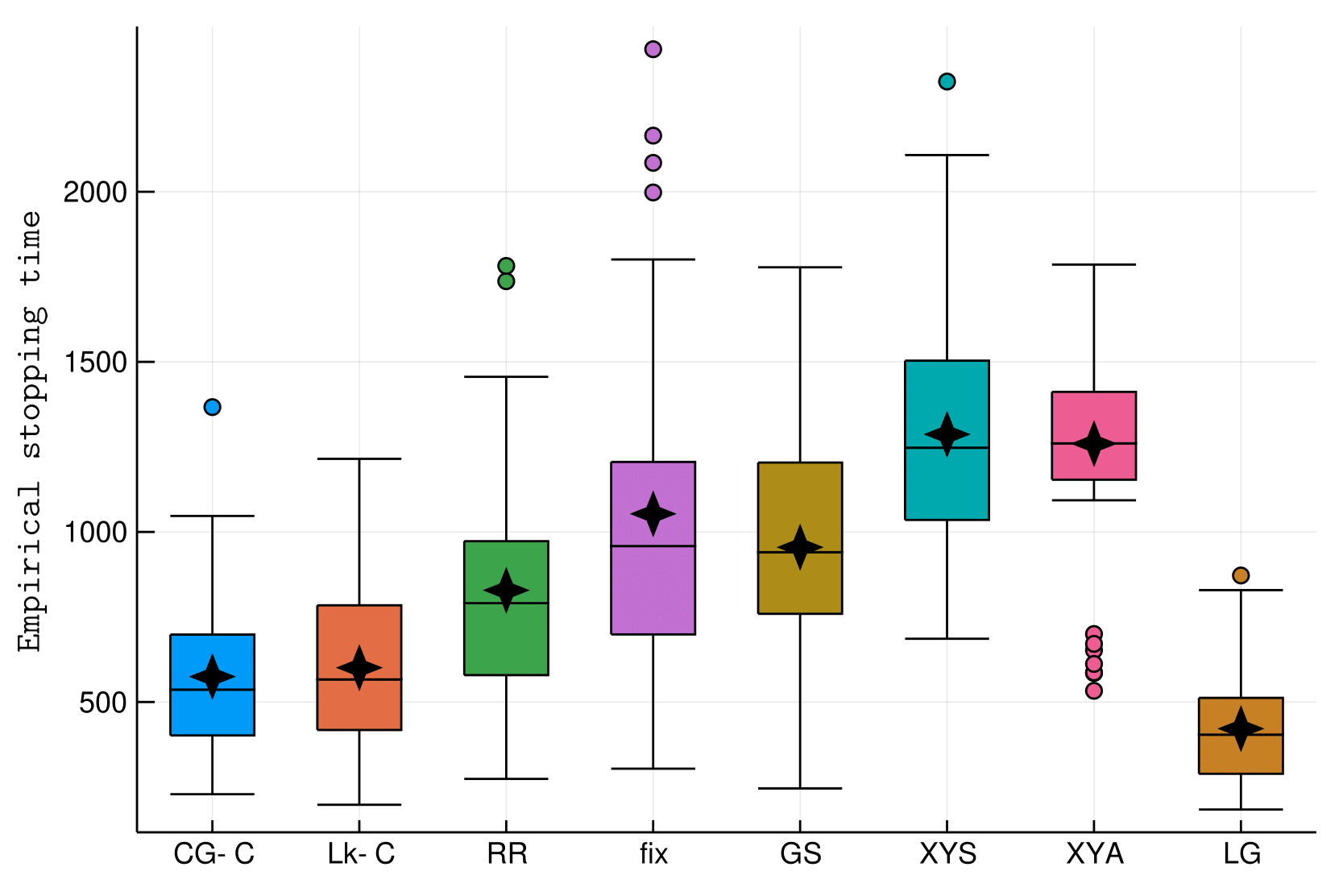
Random unit sphere (with different dimension)
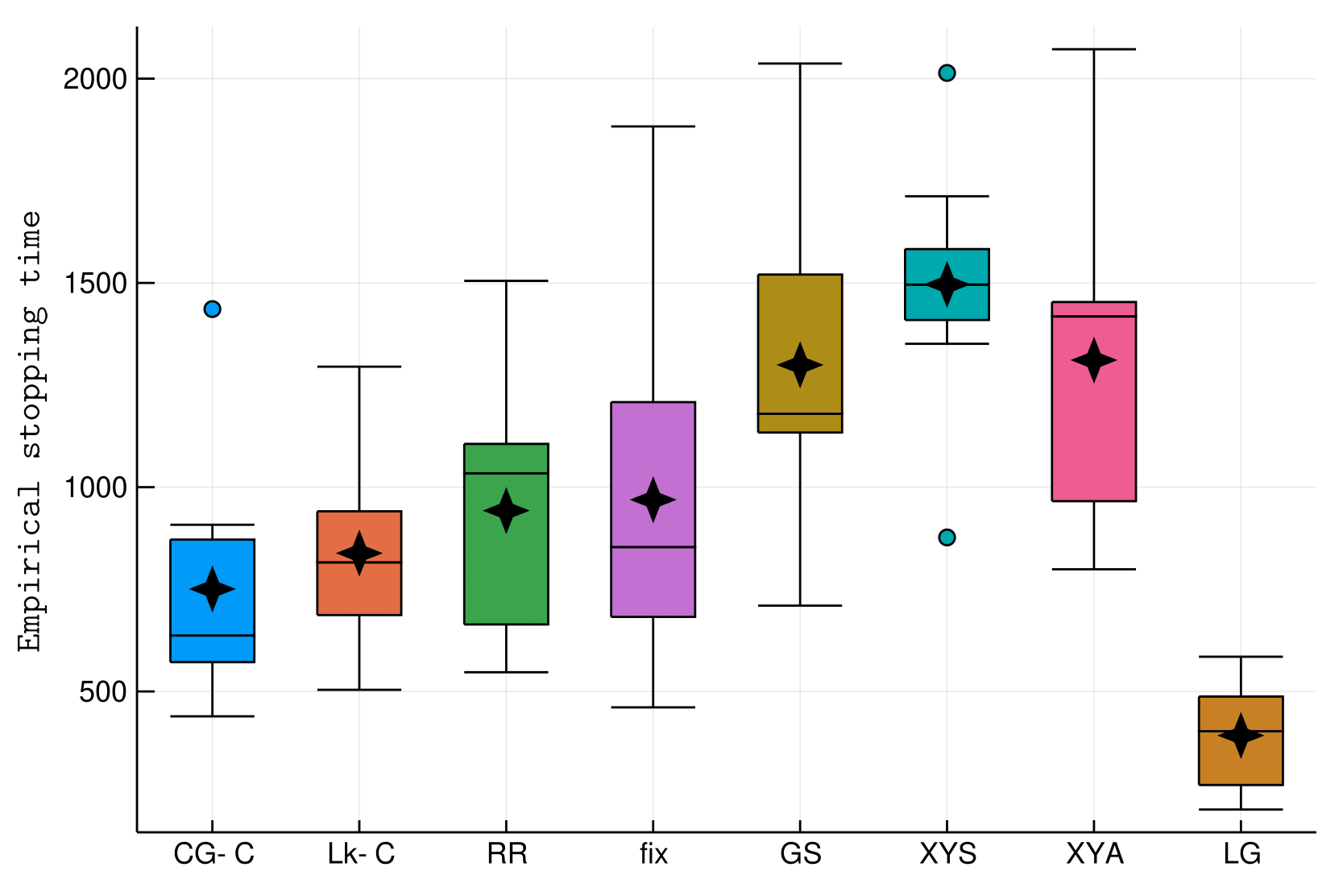
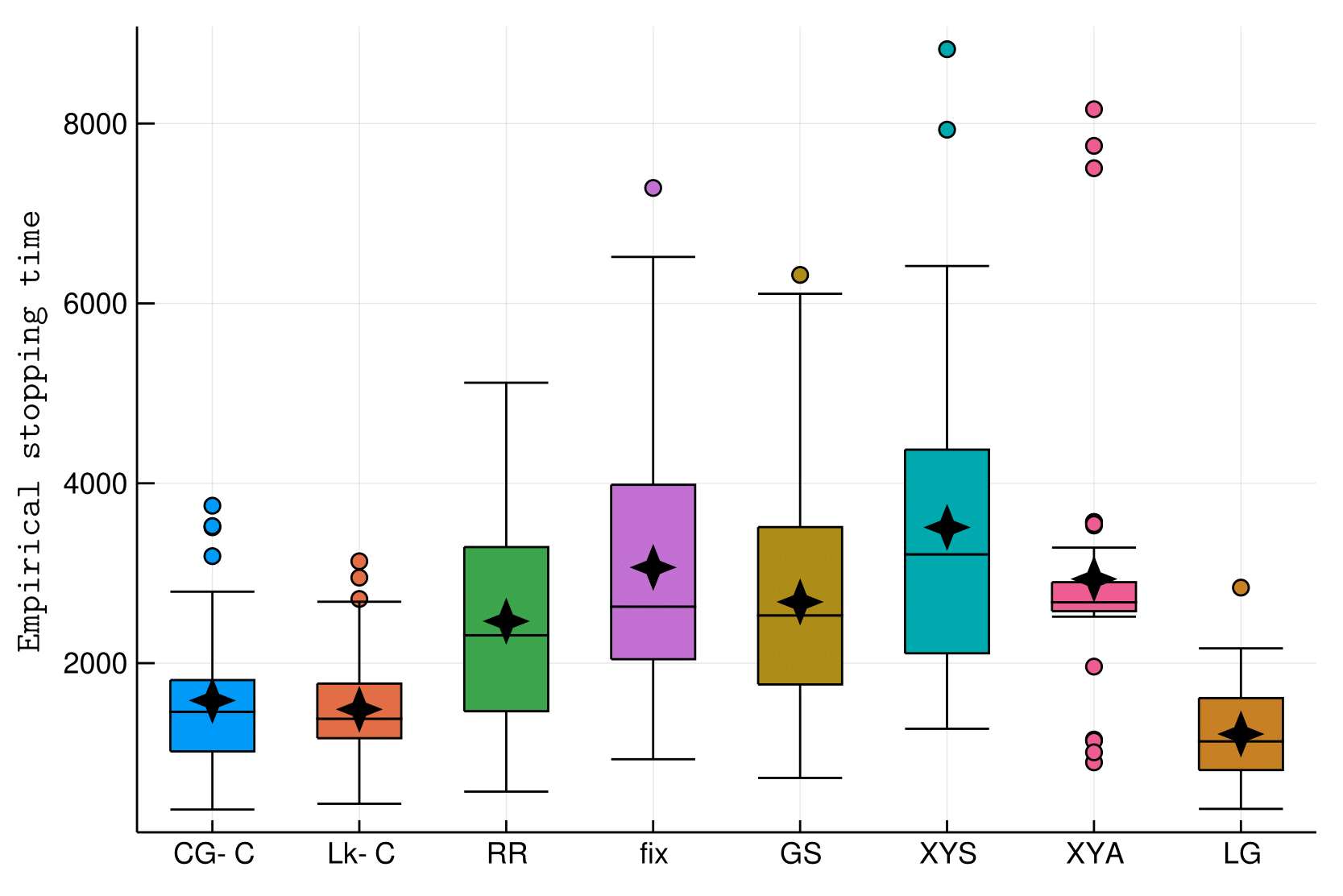
- Can be done with Track-n-Stop (Garivier and Kaufmann, 2016)
- Recent work on the topic: Jedra and Proutière (2020); Katz-Samuels et al. (2020); Zaki et al. (2020); Yang and Tan (2021)
Part 2: Infinite or Continuous Search Space
-
Continuum-armed bandits: \(f\) lies in some metric space
-
Infinitely-armed bandits (Berry et al., 1997; Wang et al., 2008; Bonald and Proutière, 2013; Carpentier and Valko, 2015): arms drawn from some reservoir distribution
HPO as continuum-armed bandits?
- Tree-search algorithm GPO (ALT 19)
- See also Munos (2011), Valko et al. (2013), Azar et al. (2014), Grill et al. (2015), Bartlett et al. (2019), Torossian et al. (2019), Hadiji (2019)
TTTS Applied to HPO
We tackle hyper-parameter tuning for supervised learning tasks
- global optimisation task: \(\min\{f(\lambda):\lambda\in\Omega\}\)
- \(f(\lambda) \triangleq \mathbb{E}\left[\ell\left(Y,\hat g_{\lambda}^{\,(n)}(X)\right) \right]\) measures the generalization power
Problem formulation
Problem formulation
We see the problem as BAI in a stochastic infinitely-armed bandit: arm means are drawn from some reservoir distribution \(\nu_0\)
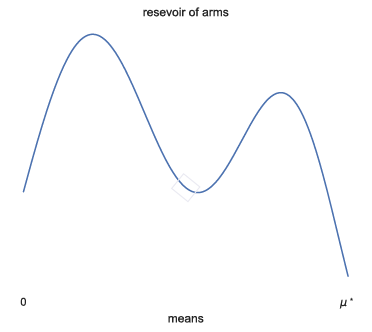
- In each round:
- (optional) query a new arm from \(\nu_0\)
- sample an arm that was previously queried
Goal: output an arm with mean close to \(\mu^\star\)
Problem formulation
HPO as a BAI problem
| BAI | HPO |
|---|---|
| query \(\nu_0\) | pick a new configuration \(\textcolor{yellow}{\lambda}\) |
| sample an arm | train the classifier |
| reward | cross-validation loss |
How?
Dynamic Top-Two Thompson Sampling (ICML-AutoML 20)
- Beta-Bernoulli Bayesian bandit model
- a uniform prior over the mean of new arms


In summary: in each round, query a new arm endowed with a Beta(1,1) prior, without sampling it, and run TTTS on the new set of arms
How?
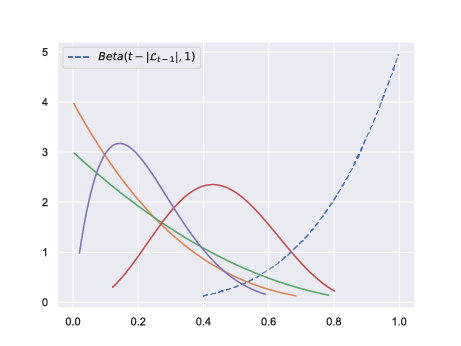
Order statistic trick
With \(\mathcal{L}_{t-1}\) the list of arms that have been effectively sampled at time \(t\), we run TTTS on the set \(\mathcal{L}_{t-1} \cup \{\mu_0\}\) where \(\mu_0\) is a pseudo-arm with posterior Beta(\(t-|\mathcal{L}_{t-1}|, 1\)).
Experiments
Setting
| Classifier | Hyper-parameter | Type | Bounds |
|---|---|---|---|
| SVM | C | \(\mathbb{R}^+\) | \(\left[ 10^{-5}, 10^{5} \right]\) |
| \(\gamma\) | \(\mathbb{R}^+\) | \(\left[ 10^{-5}, 10^{5} \right]\) | |
| MLP | hidden layer size | Integer | \(\left[ 5, 50 \right]\) |
| \(\alpha\) | \(\mathbb{R}^+\) | \(\left[ 0, 0.9 \right]\) | |
| learning rate init | \(\mathbb{R}^+\) | \(\left[ 10^{-5}, 10^{-1} \right]\) |
Experiments
Some results (I)
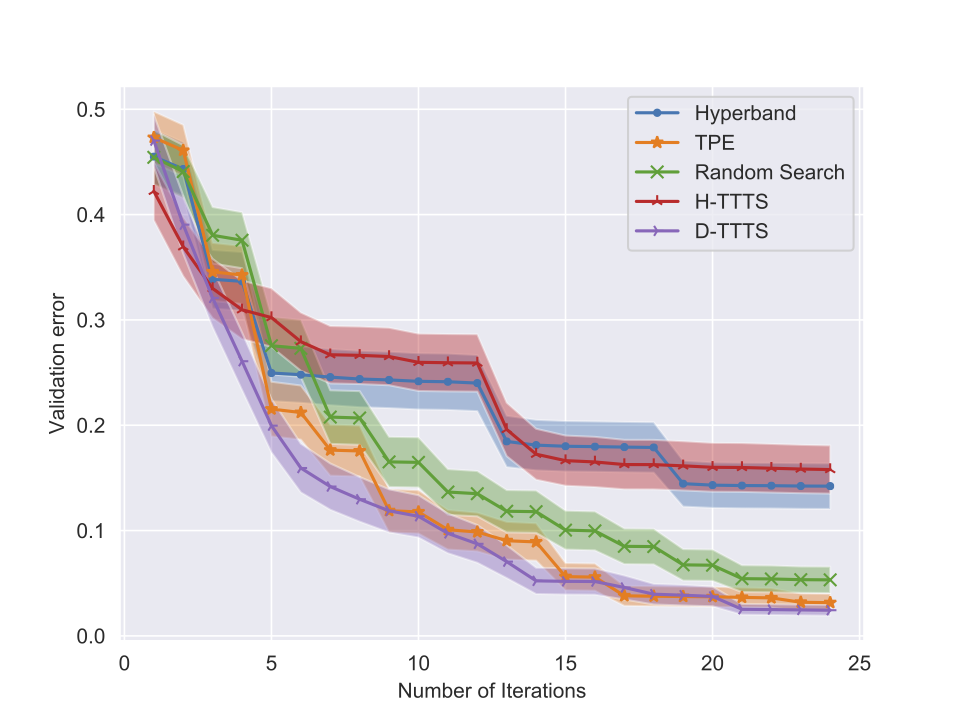
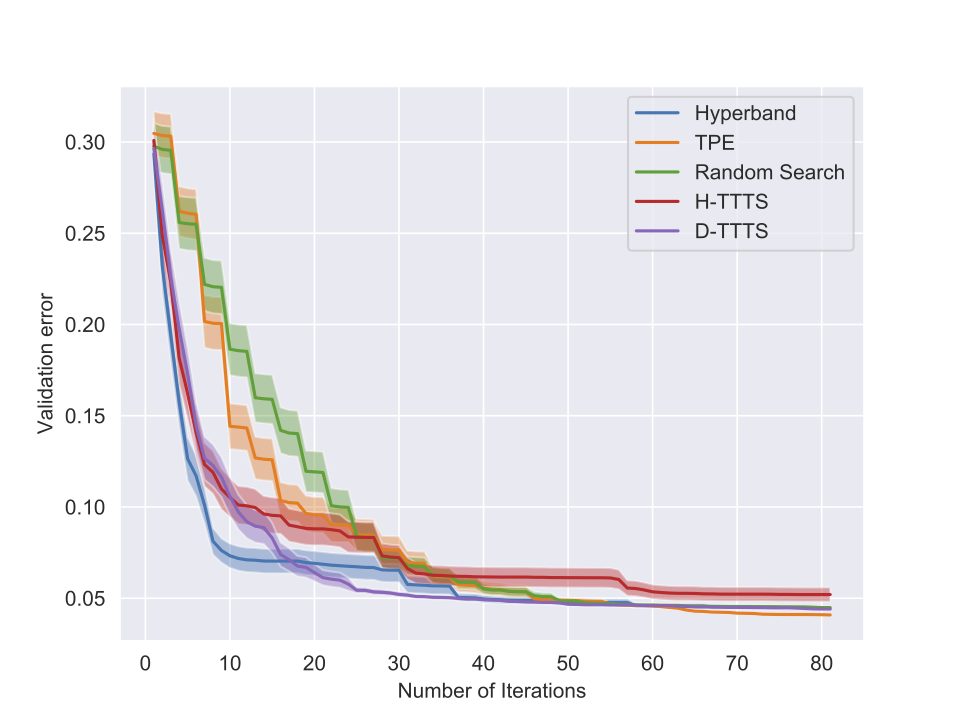
Experiments
Some results (II)
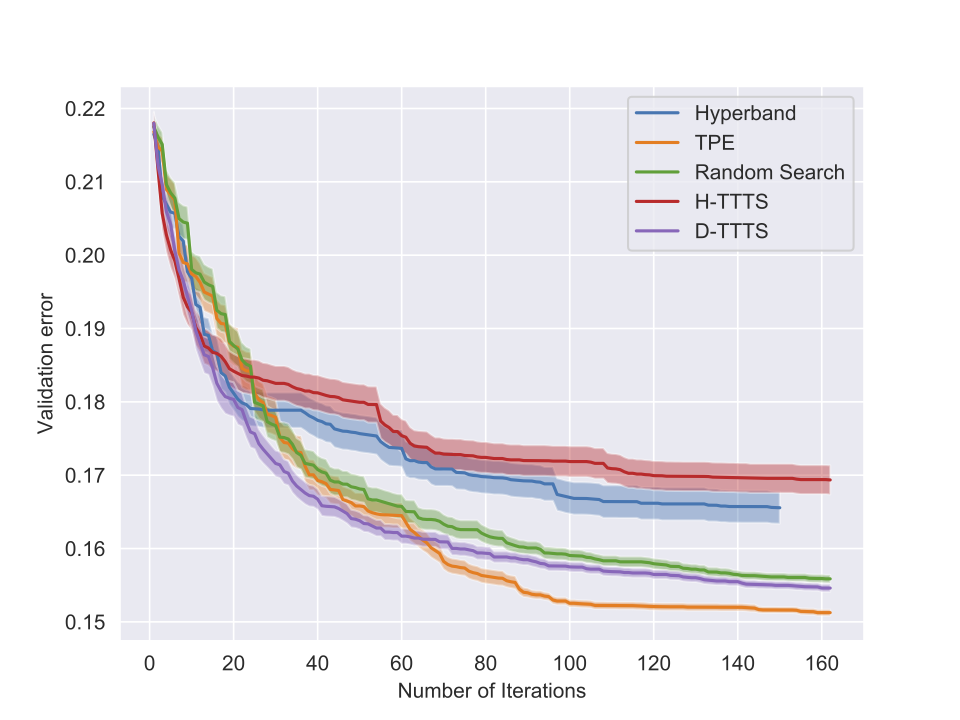
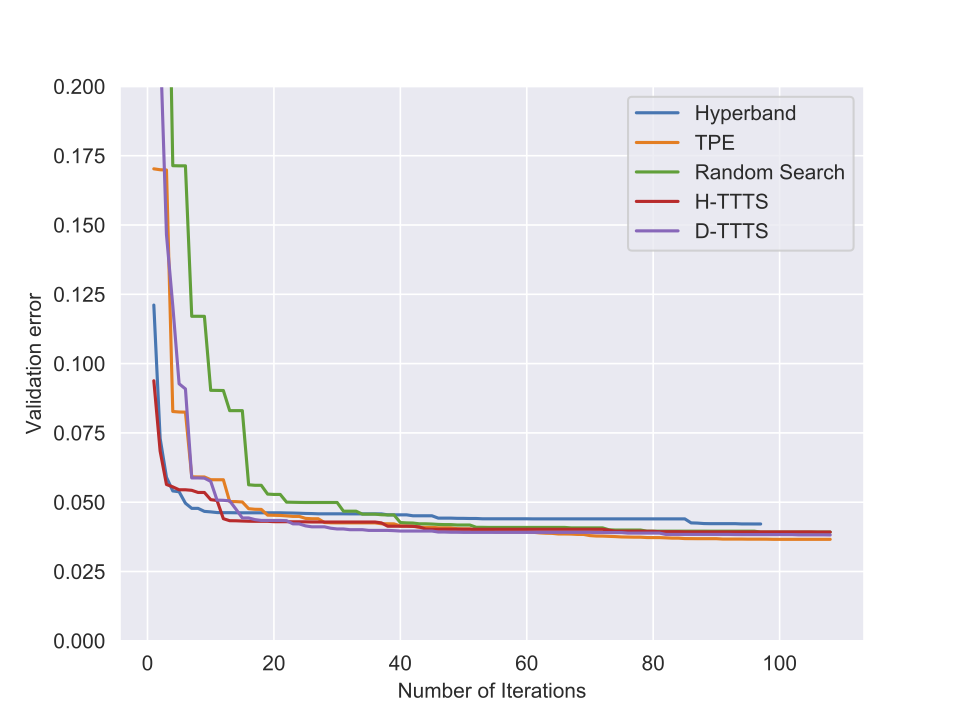
Perspectives
- Direct follow-ups
- Efficient Bayesian algorithms for linear BAI or even more general structure
- Finite-time analysis for TTTS/T3C?
- HPO, AutoML...
- Task-specific rather than task-agnostic
- Reinforcement learning
- Extension of contextual bandits
- e.g. best-policy identification
- Societal impact: safety, privacy, fairness...
References
- Presentation based on:
- Shang et al., 2019: General parallel optimisation without a metric (ALT 2019)
- Shang et al., 2020a: Fixed-confidence guarantees for Bayesian best-arm identification (AISTATS 2020)
- Shang et al., 2020b: A simple dynamic bandit algorithm for hyper-parameter tuning (ICML-AutoML 2019)
- Degenne et al., 2020: Gamification of pure exploration for linear bandits (ICML 2020)
References
- Other references
- Simple Bayesian algorithms for best arm identification, Russo (COLT 2016)
- Almost optimal exploration in multi-armed bandits, Karnin et al. (ICML 2013)
- Hyperband: Bandit-based configuration evaluation for hyperparameter optimization, Li et al. (ICLR 2017)
- Improving the expected improvement algorithm, Qin et al. (NeurIPS 2017)
- Simple regret for infinitely many armed bandits, Carpentier and Valko (ICML 2015)