Bayesian
Best-Arm Identification
and Beyond
Thursday, December 17th, 2020
Introduction
What
Given a collection of unknown measurement distributions.
$$\nu_1: \mu_1, \nu_2: \mu_2, \cdots, \nu_K: \mu_K$$
Research questions
- Regret minimization: trade-off between exploration and exploitation
- Best-arm identification: pure exploration
-
$$\mu^\star = \color{red}{\max}_i \mu_i$$
$$I^\star = \color{red}{\operatorname{arg\,max}}_i \mu_i$$
Motivation
(Source: Julie Paci)
Outline
- Bayesian Best-Arm Identification
- Application to Hyper-parameter Optimization (HPO)
- Further discussion
Bayesian Best-Arm Identification
Formally, a BAI algorithm is composed of:
- a sampling rule $\hat{I}$
- a stopping rule $\tau$
- fixed-budget: stops when reach the budget $\tau = n$
- fixed-confidence: stops when the probability of outputting a wrong arm is less than $\delta$, minimize $\expectedvalue[\tau_\delta]$
- a decision rule
- outputs a guess $J_\tau$ of the best arm $I^\star$ when the algorithm stops
We are interested in Top-Two Thompson Sampling (Russo, 2016)
A prior distribution $\Pi_1$ over $\Theta$, $\mu\in\Theta$
$(Y_{1,I_1},\cdots,Y_{n-1,I_{n-1}}) → \Pi_n$
\[ \pi_n(\mu') = \frac{\pi_1(\mu')L_{n-1}(\mu')}{∫_{\Theta}\pi_1(\mu'')L_{n-1}(\mu'')d\mu''} \] where \[ L_{n-1}(\mu') = ∏_{l=1}^{n-1}p(Y_{l,I_l}|\mu'_{I_l})\,. \]

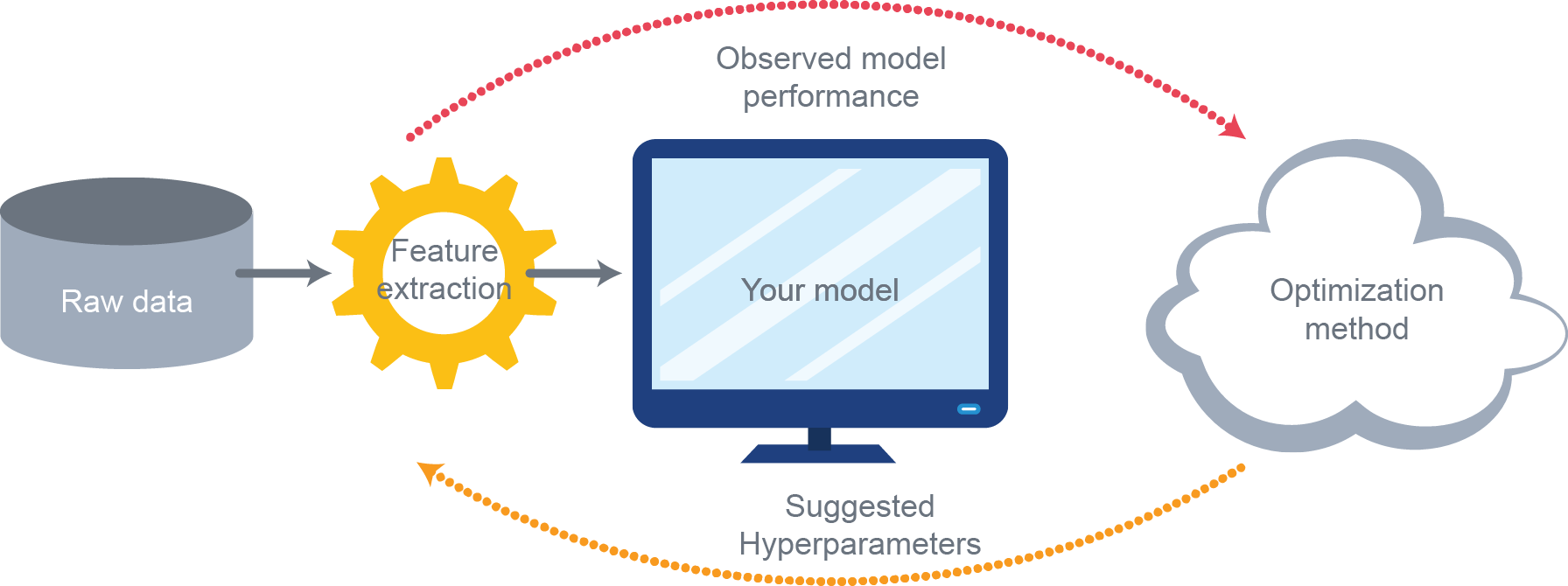
Why?
- Beyond fixed-budget and fixed-confidence: anytime BAI framework (Jun and Nowak, 2016)
- A Bayesian competitor for BAI as Thompson sampling to UCB for regret minimizing?
- It's often easier to sample from the fitted model than compute complicated optimistic estimates
- Strong practical performance?
What we know about TTTS... (Posterior convergence)
- Assumptions
- Measurement distributions are in the canonical one dimensional exponential family
- The parameter space is a bounded open hyper-rectangle
- The prior density is uniformly bounded
- The log-partition function has bounded first derivative
Theorem (Russo, 2016) Under TTTS and under the previous boundedness assumptions, it holds a.s. \[ \lim_{n\rightarrow{\infty}} -\frac{1}{n}\log(1-\alpha_{n,I^\star}) = \color{red}{\Gamma_{\beta}^\star}, \] where \begin{equation*} \quad \alpha_{n,i} \triangleq \Pi_{n}(\theta_i > \max_{j\neq i}\theta_j). \end{equation*}
What we know about TTTS... (Complexity)
Definition Let $\Sigma_K = \{\omega : \sum_{k=1}^K \omega_k = 1, \omega_k \geq 0\}$ and define for all $i\neq I^\star$ \[ C_i(\omega,\omega') \triangleq \min_{x\in\mathcal{I}} \omega d(\mu_{I^\star};x) + \omega' d(\mu_i;x), \] where $d(\mu,\mu')$ is the KL-divergence. We define \begin{eqnarray*} \Gamma_{\beta}^\star \triangleq \max_{\substack{\omega \in \Sigma_K\\\omega_{I^\star}=\beta}}\min_{i\neq I^\star} C_i(\omega_{I^\star},\omega_i).\label{def:GammaBeta} \end{eqnarray*}
In particular, for Gaussian bandits... \[ \Gamma_{\beta}^\star = \max_{\omega:\omega_{I^\star}=\beta}\min_{i\neq I^\star} \frac{(\mu_{I^\star}-\mu_i)^2}{2\sigma^2(1/\omega_i+1/\beta)}. \]
What we want to know about TTTS...
- Can we 'relax' the aforementioned assumptions?
- What can we say about the sample complexity in the fixed-confidence setting?
- Lower bound Under any $\delta$-correct strategy satisfying $T_{n,I^\star}/n \rightarrow \beta$, \[\liminf_{\delta \rightarrow 0}\frac{\expectedvalue[\tau_\delta]}{\ln(1/\delta)} \geq \frac{1}{\Gamma^\star_\beta}.\]
- Can we have finite-time guarantees?
Bayesian Best-Arm Identification
- Theoretical insights
Main results
Posterior convergence
Theorem 1 (Shang et al., 2020) Under TTTS, for Gaussian bandits with Gaussian priors, it holds a.s. \[ \lim_{n\rightarrow{\infty}} -\frac{1}{n}\log(1-\alpha_{n,I^\star}) = \color{red}{\Gamma_{\beta}^\star}. \]
Theorem 2 (Shang et al., 2020) Under TTTS, for Bernoulli bandits and uniform priors, it holds a.s. \[ \lim_{n\rightarrow{\infty}} -\frac{1}{n}\log(1-\alpha_{n,I^\star}) = \color{red}{\Gamma_{\beta}^\star}. \]
Main results
Sample complexity
Theorem 3 (Shang et al., 2020) The TTTS sampling rule coupled with the Chernoff stopping rule form a $\delta$-correct BAI strategy. If all arm means are distinct, \[ \limsup_{\delta\rightarrow{0}} \frac{\expectedvalue[\tau_{\delta}]}{\log(1/\delta)} \leq \frac{1}{\color{red}{\Gamma_{\beta}^\star}}. \]
Recall (Lower bound): \[\liminf_{\delta \rightarrow 0}\frac{\expectedvalue[\tau_\delta]}{\ln(1/\delta)} \geq \frac{1}{\color{red}{\Gamma^\star_\beta}}.\]
Proof sketch
$\delta$-correctness
Stopping rule: \begin{equation} \tau_\delta^{\text{Ch.}} ≜ \inf \left\lbrace n \in \mathbb{N} : \max_{i \in \mathcal{A}} \min_{j \in \mathcal{A} \setminus \{i\} } \color{lightskyblue}{W_{n}(i,j)} > d_{n,\delta} \right\rbrace. \end{equation}
Transportation cost: $\mu_{n,i,j} ≜ (T_{n,i}\mu_{n,i} +T_{n,j}\mu_{n,j})/(T_{n,i}+T_{n,j})$, then we define \begin{equation}\label{def:Transportation} \color{lightskyblue}{W_n(i,j)} ≜ \left\{ \begin{array}{ll} 0 & \operatorname{if} \mu_{n,j} \geq \mu_{n,i},\\ W_{n,i,j}+W_{n,j,i} & \operatorname{otherwise}, \end{array}\right. \end{equation} where $W_{n,i,j} ≜ T_{n,i} d\left(\mu_{n,i},\mu_{n,i,j}\right)$ for any $i,j$.
In particular, for Gaussian bandits: \[ \color{lightskyblue}{W_n(i,j)} = \dfrac{(\mu_{n,i}-\mu_{n,j})^2}{2\sigma^2(1/T_{n,i}+1/T_{n,j})}\mathbb{1}\{\mu_{n,j}<\mu_{n,i}\}. \]
Theorem (Shang et al., 2020) The TTTS sampling rule coupled with the Chernoff stopping rule with a threshold $d_{n,\delta} \simeq \log(1/\delta) + c\log(\log(n))$ and the recommendation rule $J_t = \operatorname{arg\,max}_i \mu_{n,i}$, form a $\delta$-correct BAI strategy.
Bayesian stopping rule: \[\tau_{\delta} ≜ \inf \left\{ n\in\mathbb{N}:\max_{i\in\mathcal{A}} \color{limegreen}{\alpha_{n,i}} \geq c_{n,\delta} \right\}\,.\]
Proof sketch
Sufficient condition for $\beta$-optimality
Lemma (Shang et al. 2020) Let $\delta,\beta\in (0,1)$. For any sampling rule which satisfies $\expectedvalue[\color{lightskyblue}{T_{\beta}^\epsilon}] < \infty$ for all $\epsilon > 0$, we have \[ \limsup_{\delta\rightarrow{0}} \frac{\expectedvalue[\tau_{\delta}]}{\log(1/\delta)} \leq \frac{1}{\Gamma_{\beta}^\star}, \] if the sampling rule is coupled with the Chernoff stopping rule.
$\color{lightskyblue}{T_{\beta}^\epsilon} ≜ \inf \left\{ N\in\mathbb{N}: \max_{i\in\mathcal{A}} \vert T_{n,i}/n-\omega_i^\beta \vert \leq \epsilon, \forall n \geq N \right\}$.
Proof sketch
Core theorem
Theorem (Shang et al. 2020) Under TTTS, $\expectedvalue[\color{lightskyblue}{T_{\beta}^\epsilon}] < +\infty$.
The proof is inspired by Qin et al. (2017), but major technical novelties are introduced. In particular, our proof is much more intricate due to the randomized nature of the two candidate arms...
Bayesian Best-Arm Identification
- Computational improvement
TTTS

T3C (Top-Two Transportation Cost)

Main results
Sample complexity
Theorem (Shang et al. 2020) The T3C sampling rule coupled with the Chernoff stopping rule form a $\delta$-correct BAI strategy. If all arm means are distinct, \[ \limsup_{\delta\rightarrow{0}} \frac{\expectedvalue[\tau_{\delta}]}{\log(1/\delta)} \leq \frac{1}{\color{red}{\Gamma_{\beta}^\star}}. \]
Illustrations
Time consumption
| Sampling rule | T3C | TTTS | Uniform |
|---|---|---|---|
| Exec. time (s) | $1.6 \times 10^{-5}$ | $2.3 \times 10^{-4}$ | $6.0 \times 10^{-6}$ |
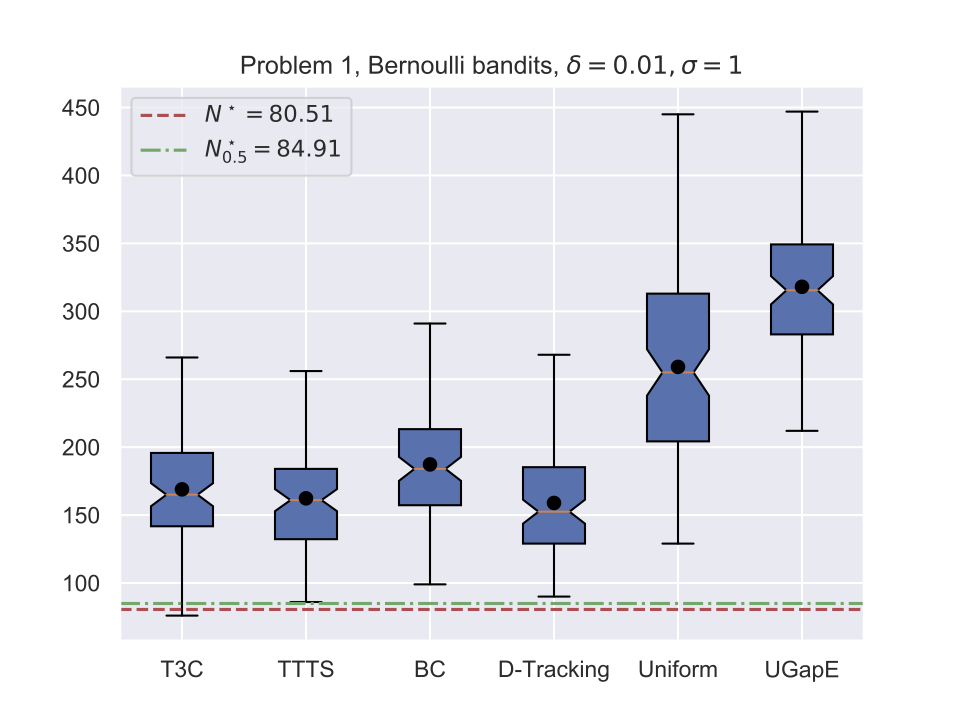
Illustrations
Average stopping time (Bernoulli)
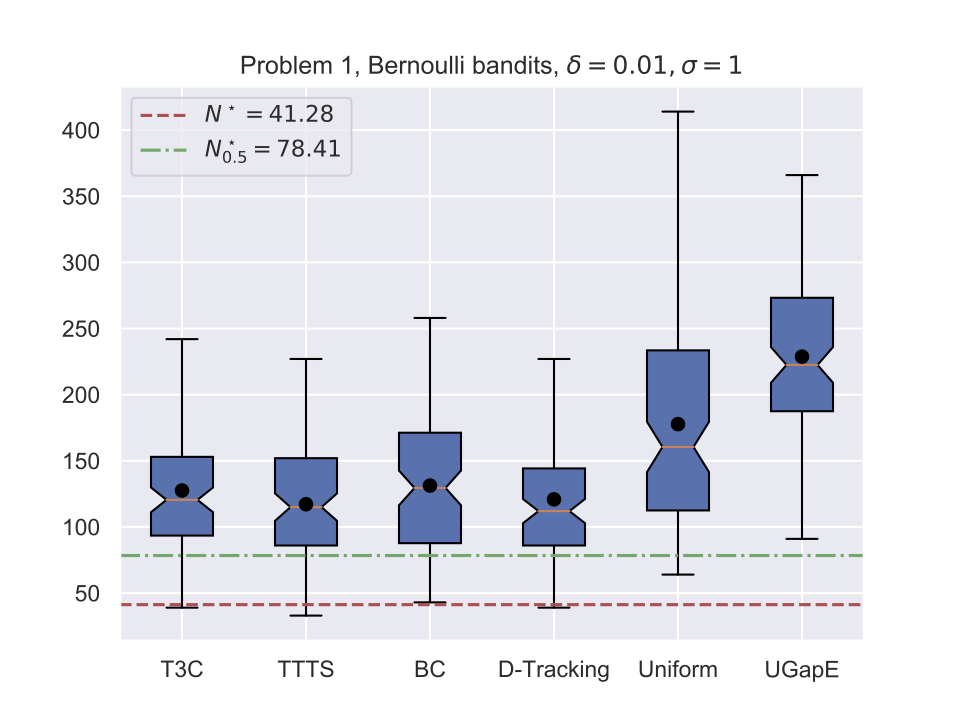
Illustrations
Average stopping time (Gaussian)
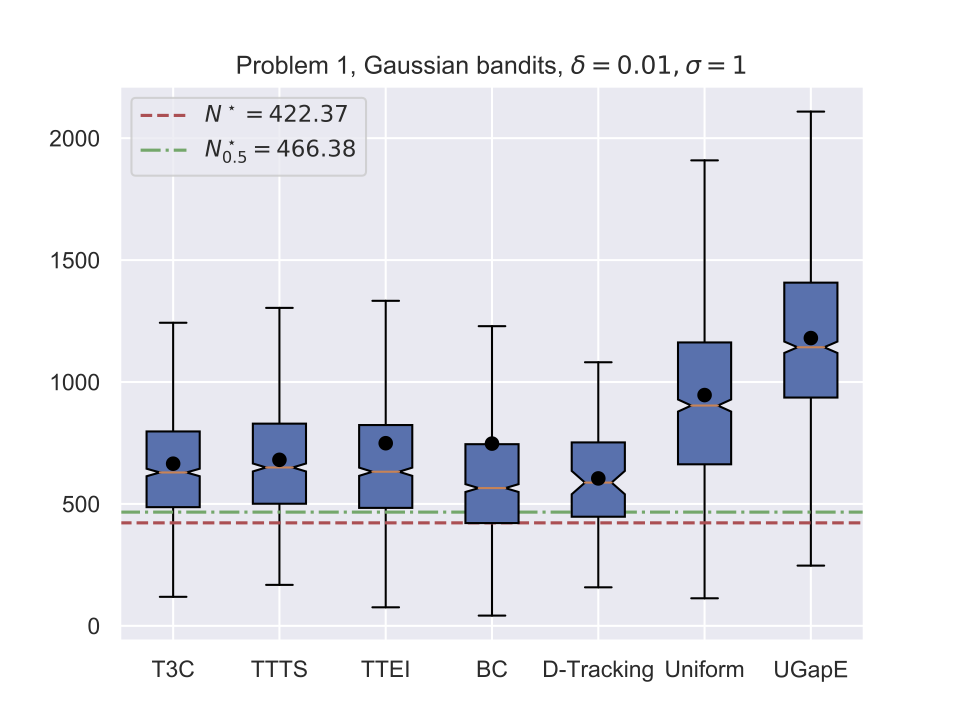
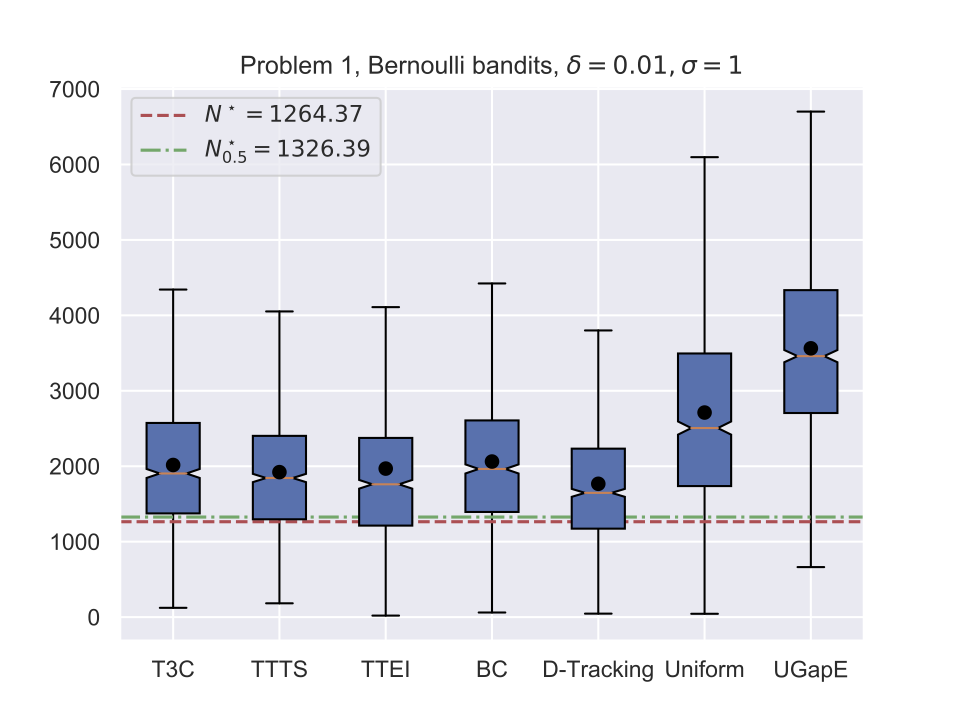
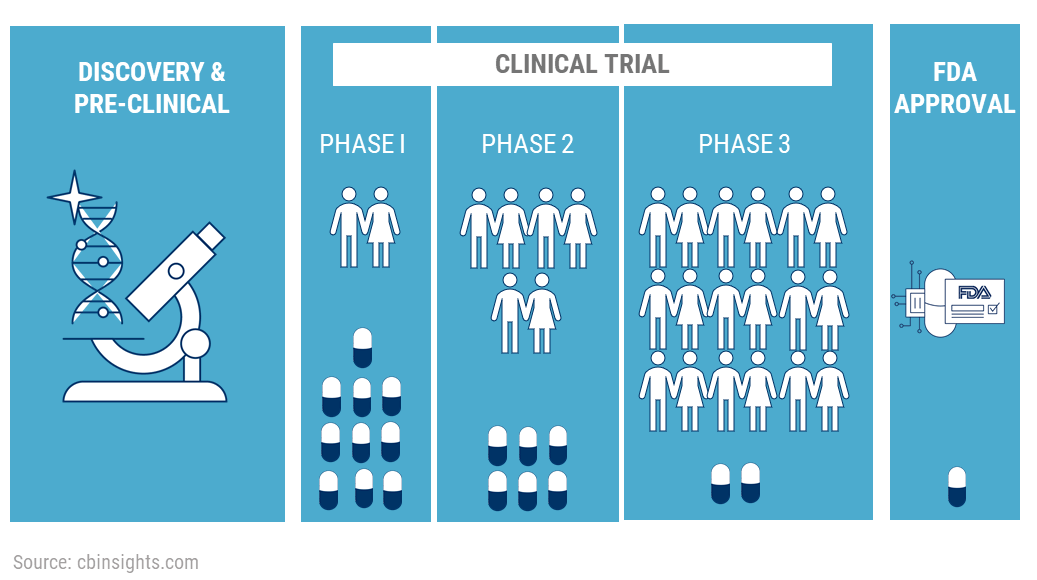
Application to Hyper-paramter Optimization
Problem formulation
We tackle hyper-parameter tuning for supervised learning tasks:
- global optimisation task: $\min\{f(\lambda):\lambda\in\Omega\}$
- $f(\lambda) \triangleq \mathbb{E}\left[\ell\left(Y,\hat g_{\lambda}^{\,(n)}(X)\right) \right]$ measures the generalization power
Problem formulation
We see the problem as BAI in a stochastic infinitely-armed bandit: arm means are drawn from some reservoir distribution $\nu_0$
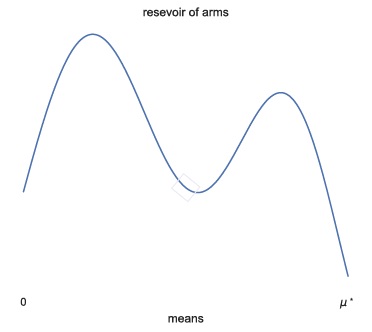
- In each round:
- (optional) query a new arm from $\nu_0$
- sample an arm that was previously queried
Goal: output an arm with mean close to $\mu^\star$
Problem formulation
HPO as a BAI problem
| BAI | HPO |
|---|---|
| query $\nu_0$ | pick a new configuration $\lambda$ |
| sample an arm | train the classifier |
| reward | cross-validation loss |
How? - DTTTS
Dynamic Top-Two Thompson Sampling
- In this talk...
- Beta-Bernoulli Bayesian bandit model
- a uniform prior over the mean of new arms


In summary: in each round, query a new arm endowed with a Beta(1,1) prior, without sampling it, and run TTTS on the new set of arms
How? - DTTTS
Order statistic trick
With $\mathcal{L}_{t-1}$ the list of arms that have been effectively sampled at time $t$, we run TTTS on the set $\mathcal{L}_{t-1} \cup \{\mu_0\}$ where $\mu_0$ is a pseudo-arm with posterior Beta($t-|\mathcal{L}_{t-1}|, 1$).
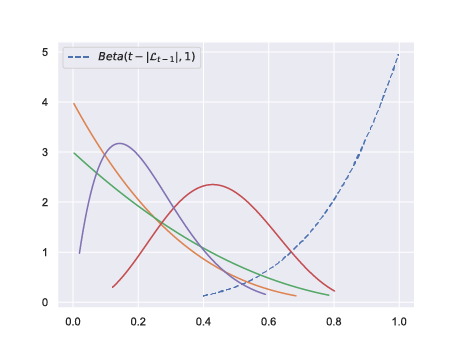
Rationale
- TTTS is anytime for finitely-armed bandits
- The flexibility of this Bayesian algorithm allows to propose a dynamic version for the infinite BAI
- Unlike previous approaches (for infinite-armed bandits or HPO), DTTTS does not need to fix the number of arms queried in advance, and naturally adapts to the difficulty of the task
- choose a problem-dependent number of arms
- pull arms optimistically
- equally divide the budget $B$ into $m$ brackets
- run sequential halving (Karnin et al., 2013) over a fixed number $n$ of configurations in each bracket
- trade-off between $B/mn$ and $n$
SiRI (Carpentier and Valko, 2015) as an example for infinite-armed bandits:
Hyperband (Li et al., 2017) as an example for HPO
Experiments
Setting
| Classifier | Hyper-parameter | Type | Bounds |
|---|---|---|---|
| SVM | C | $\mathbb{R}^+$ | $\left[ 10^{-5}, 10^{5} \right]$ |
| $\gamma$ | $\mathbb{R}^+$ | $\left[ 10^{-5}, 10^{5} \right]$ | |
| MLP | hidden layer size | Integer | $\left[ 5, 50 \right]$ |
| $\alpha$ | $\mathbb{R}^+$ | $\left[ 0, 0.9 \right]$ | |
| learning rate init | $\mathbb{R}^+$ | $\left[ 10^{-5}, 10^{-1} \right]$ |
Experiments
Some results (I)
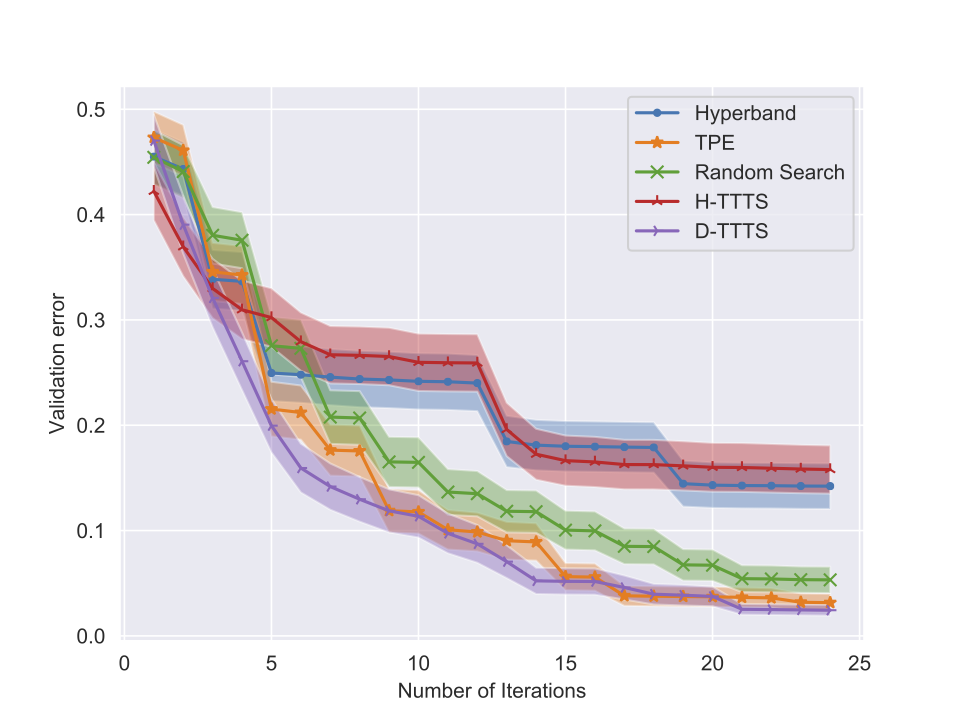
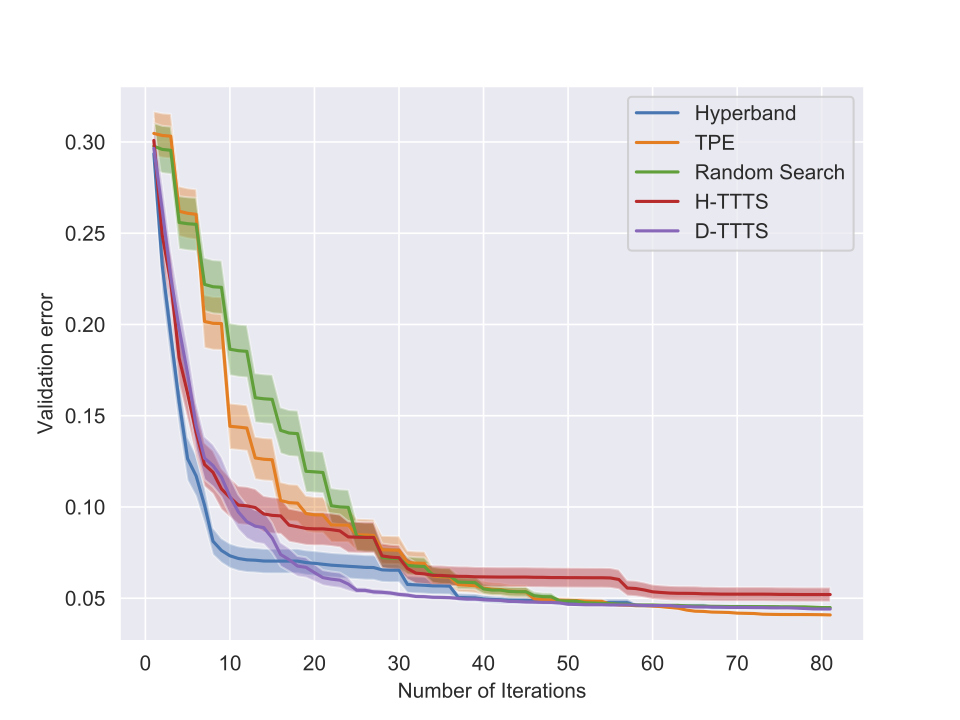
Experiments
Some results (II)
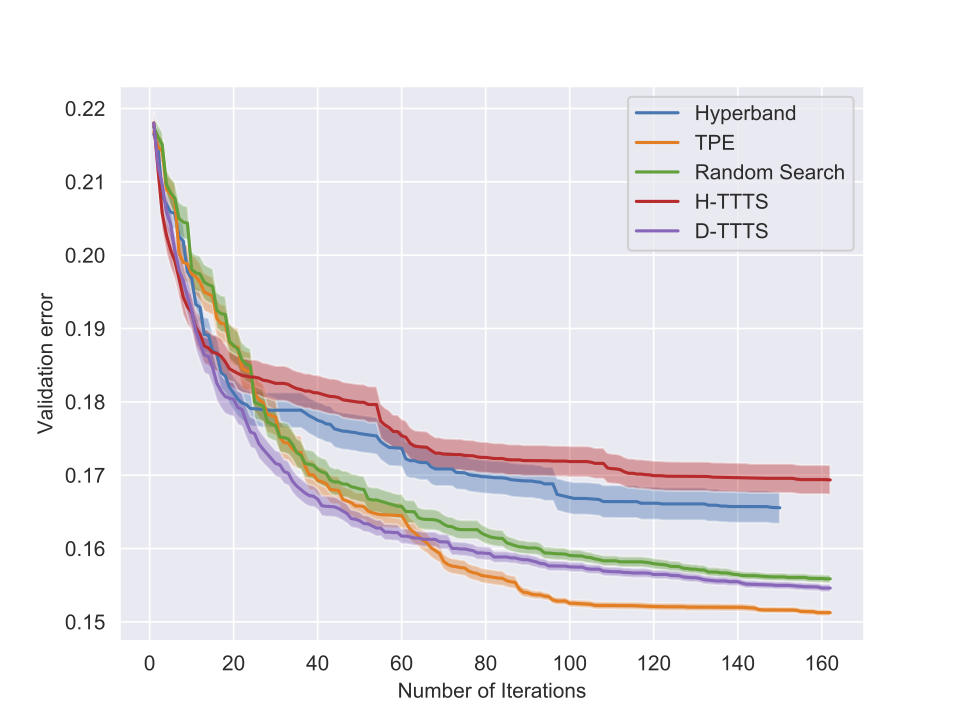
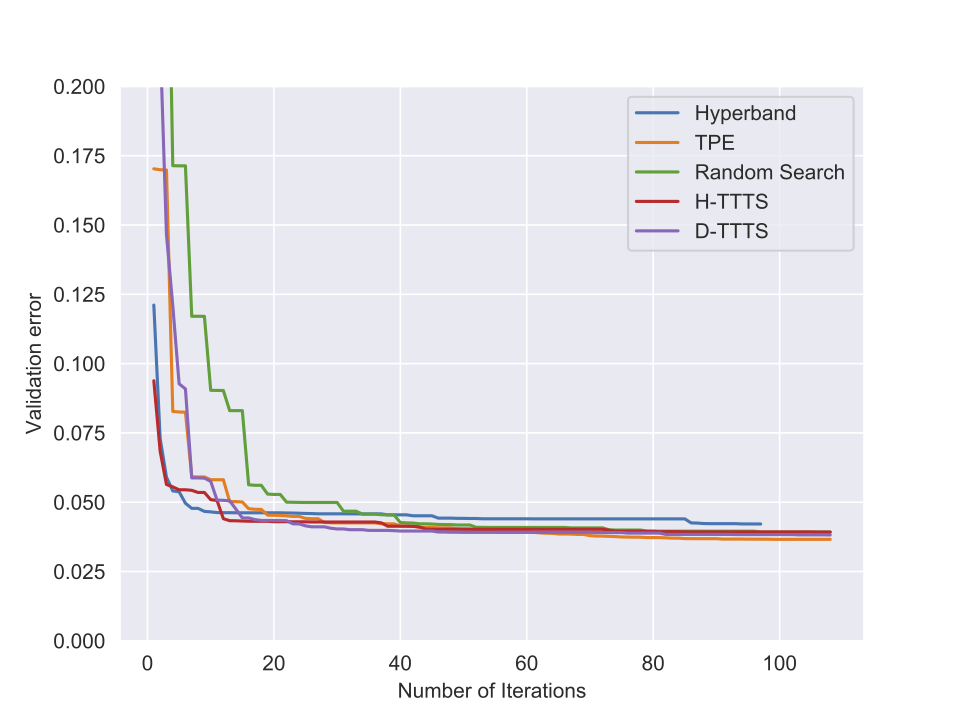
Further Discussion
BAI for linear bandits
In the linear case:
- each arm (context) is a vector $x\in\mathbb{R}^d$
- unknown regression parameter $\theta^\star\in\mathbb{R}^d$
- $\mu_i = x_i^T\theta^\star$
- goal: $x^\star ≜ \operatorname{arg\,max}_{x\in\mathcal{X}}x^T\theta^\star$
BAI for linear bandits
- Can TTTS/T3C be extended to the linear case? (working paper)
- Saddle-point approach to achieve asymptotic optimality (Degenne, Menard, Shang and Valko, 2020)
References
- Presentation based on
- Fixed-confidence guarantees for Bayesian best-arm identification (AISTATS 2020)
- A simple dynamic bandit algorithm for hyper-parameter tuning (ICML-AutoML 2019)
- Gamification of pure exploration for linear bandits (ICML 2020)
- Other references
- Simple Bayesian algorithms for best arm identification, Russo (COLT 2016)
- Almost optimal exploration in multi-armed bandits, Karnin et al. (ICML 2013)
- Hyperband: Bandit-based configuration evaluation for hyperparameter optimization, Li et al. (ICLR 2017)
- Improving the expected improvement algorithm, Qin et al. (NeurIPS 2017)
- Simple regret for infinitely many armed bandits, Carpentier and Valko (ICML 2015)
Future Plan at RIKEN
Beysian Learning and Reinforcement learning
- The general Bayesian learning framework by Khan and Rue (2019) \[ \min_{q(\theta)\in\mathcal{Q}} \expectedvalue_{q(\theta)}\left[\ell(\theta))\right] - \mathcal{H}(q)\,. \]
- Link to RL (in particular policy-based methods like A2C, PPO, etc)
- Environment $\rightarrow M = (\mathcal{S}, \mathcal{A}, P, R)$
- Stochastic policies $\{\pi_\theta\}_{\theta\in\Theta}$.
- \[ \theta^\star = \operatorname{arg\,max} \expectedvalue_{\pi_\theta}\left[ \sum_{t=0}^\infty \gamma^t r(s_t, a_t) \middle| s_0 \sim \rho \right] \]
RL as Inference
- PGM s.t. infer $p(a_t|s_t,\theta) = \pi_{\theta}(a_t|s_t) →$ optimal policy (see Levine, 2018 for a survey)
- Introduce an additional binary random variable $\mathcal{O}_t$ \[ p(\mathcal{O}_t=1|s_t,a_t) = \exp(r(s_t,a_t)) → p(a_t|s_t,\mathcal{O}_{t:T})\,. \]
- It is sufficient to compute \[ \beta_t(s_t,a_t) = p(\mathcal{O}_{t:T}|s_t,a_t)\,, \] and \[ \beta_t(s_t) = p(\mathcal{O}_{t:T}|s_t) = ∫_{\mathcal{A}}\beta_t(s_t,a_t)p(a_t|s_t)\,. \]
Online Approximate Bayesian Inference
- Theoretical groundings for online Bayesian inference algorithms
- e.g. generalization bound for online VI (Chérief-Abdellatif, Alquier and Khan, 2020)
Direct Follow-ups and Other Perspectives
- Software: rlberry
- BAI for linear bandits using Bayesian machineries
- Bandits/Bayesian optimization for AutoML
- Fairness and safety constraints